

Machine learning and artificial intelligence are becoming more and more ubiquitous and an integral part of our lives. Along with the rise of machine learning and artificial intelligence, the concern around machine learning bias is also increasing.
In this article, we will talk about one of the hot topics in Machine Learning Ethics — how to reduce machine learning bias. We shall also discuss the tools and techniques for the same.
Machine Learning Bias
Machine learning bias, also sometimes known as bias in artificial intelligence, is a phenomenon that occurs when an algorithm produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process.
Bias could be prejudice in favor or against a person, group, or thing that is considered to be unfair.
Examples of machine learning bias
1.Word Embeddings: The introduction of word embedding was a revolution for various natural language understanding problem as they were able to capture the simple relationship between words:
King — Man + Woman = Queen
The same word embeddings were also captured the following relationships:
Computer-programmer — Man + Woman = Home-Maker
2. Amazon’s AI recruiting tool: Amazon, a few years ago, scrapped an artificial-intelligence-based recruiting tool. Which reportedly had taught itself that male candidates were preferable. It penalized resumes that included the word “women’s,” as in “women’s chess club captain.” And it also downgraded graduates of women’s colleges.
Amazon edited the programs to make them neutral to these particular terms. But that was no guarantee that the machines would not devise other ways of sorting candidates that could prove discriminatory.
3. COMPAS (Correctional Offender Management Profiling for Alternative Sanctions): This is perhaps the most talked-about example of machine learning bias. COMPAS was an algorithm used in US court systems to predict the likelihood a defendant would become a recidivist. The model predicted twice as many false positives for recidivism for black offenders (45%) than white offenders (23%)
Now we have understood machine learning bias seen the drastic impact it could have on our lives. Let us understand what the different types of biases or the different factors causing machine learning bias are.
Types/causes of machine learning bias
Data Bias
Suppose certain elements of a dataset are more heavily weighted and/or represented than others. Then the resulting machine learning bias could be attributed to the data.
Data bias can further be specified into the following types:
1. Sample bias/ Selection Bias: the data used is either not large enough or representative enough to teach the system.
For example, If a facial recognition system trained primarily on images of white men. These models have considerably lower levels of accuracy with women and people of different ethnicities.
2. Prejudice Bias /Association Bias: the data used to train the system reflects existing prejudices, stereotypes, and faulty societal assumptions, thereby introducing those same real-world biases into the machine learning itself.
For example, using data about medical professionals that includes only female nurses and male doctors would thereby perpetuate a real-world gender stereotype about healthcare workers in the computer system.
3. Exclusion Bias: it’s a case of deleting valuable data thought to be unimportant. It can also occur due to the systematic exclusion of certain information.
For example, imagine you have a dataset of customer sales in America and Canada. 98% of the customers are from America, so you choose to delete the location data thinking it is irrelevant. However, this means your model will not pick up on the fact that your Canadian customers spend two times more.
4. Measurement bias: the data collected for training differs from that collected in the real world or when faulty measurements result in data distortion.
For example, in image recognition datasets, where the training data is collected with one type of camera, but the production data is collected with a different camera. Measurement bias can also occur due to inconsistent annotation during the data labeling stage of a project.
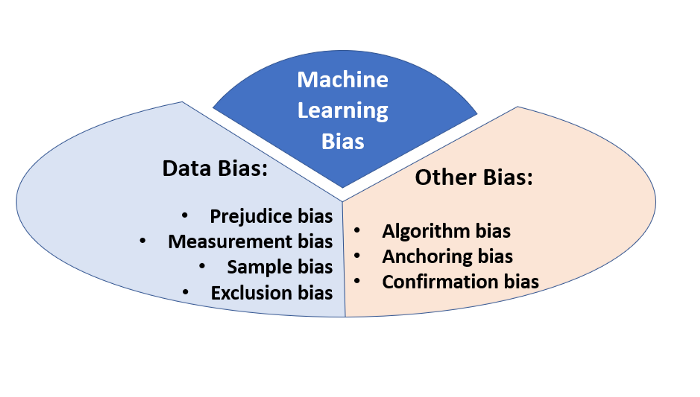
There could be other types of machine learning bias whose origins are NOT in data. Examples of such machine learning bias include:
1. Algorithm bias: when there’s a problem within the algorithm that performs the calculations that power the machine learning computations. Either the algorithm favors or unnecessarily opposes a certain section of the population.
2. Anchoring bias: occurs when choices on metrics and data are based on personal experience or preference for a specific set of data. By “anchoring” to this preference, models are built on the preferred set, which could be incomplete or even contain incorrect data leading to invalid results.
For example, if the facility collecting the data specializes in a particular demographic or comorbidity, the data set will be heavily weighted towards that information. If this set is then applied elsewhere, the generated model may recommend incorrect procedures or ignore possible outcomes because of the limited availability of the original data source.
3. Confirmation bias/Observer Bias: It leads to the tendency to choose source data or model results that align with currently held beliefs or hypotheses. The generated results and output of the model can also strengthen the end-user’s confirmation bias, leading to bad outcomes.
Practices to reduce machine learning bias
The following are some of the best practices you can follow to reduce machine learning bias:
1. Select training data that is appropriately representative and large enough to counteract common types of machine learning bias, such as sample bias and prejudice bias.
2. Test and validate to ensure that machine learning systems’ results don’t reflect bias due to algorithms or the data sets.
3. Monitor machine learning systems as they perform their tasks to ensure biases don’t creep in overtime as the systems continue to learn as they work. Subpopulation analysis is one of the smarter ways to do monitor model performance over time.
4. Use multi-pass annotation for any project where data accuracy may be prone to bias. Examples of this include sentiment analysis, content moderation, and intent recognition.
Tools & Techniques to detect & reduce machine learning bias:
In addition to the above-mentioned practices, there exist a few tools and techniques which could help to detect machine learning bias, and in some cases, even remove it.
1. Google’s What-If tool
Google’s What-If Tool (WIT) is an interactive tool that allows a user to visually investigate the machine learning bias. It provides a way to analyze data sets in addition to trained TensorFlow models.
One example of WIT is the ability to manually edit examples from a data set and see the effect of those changes through the associated model. It can also generate partial dependence plots to illustrate how predictions change when a feature is changed.
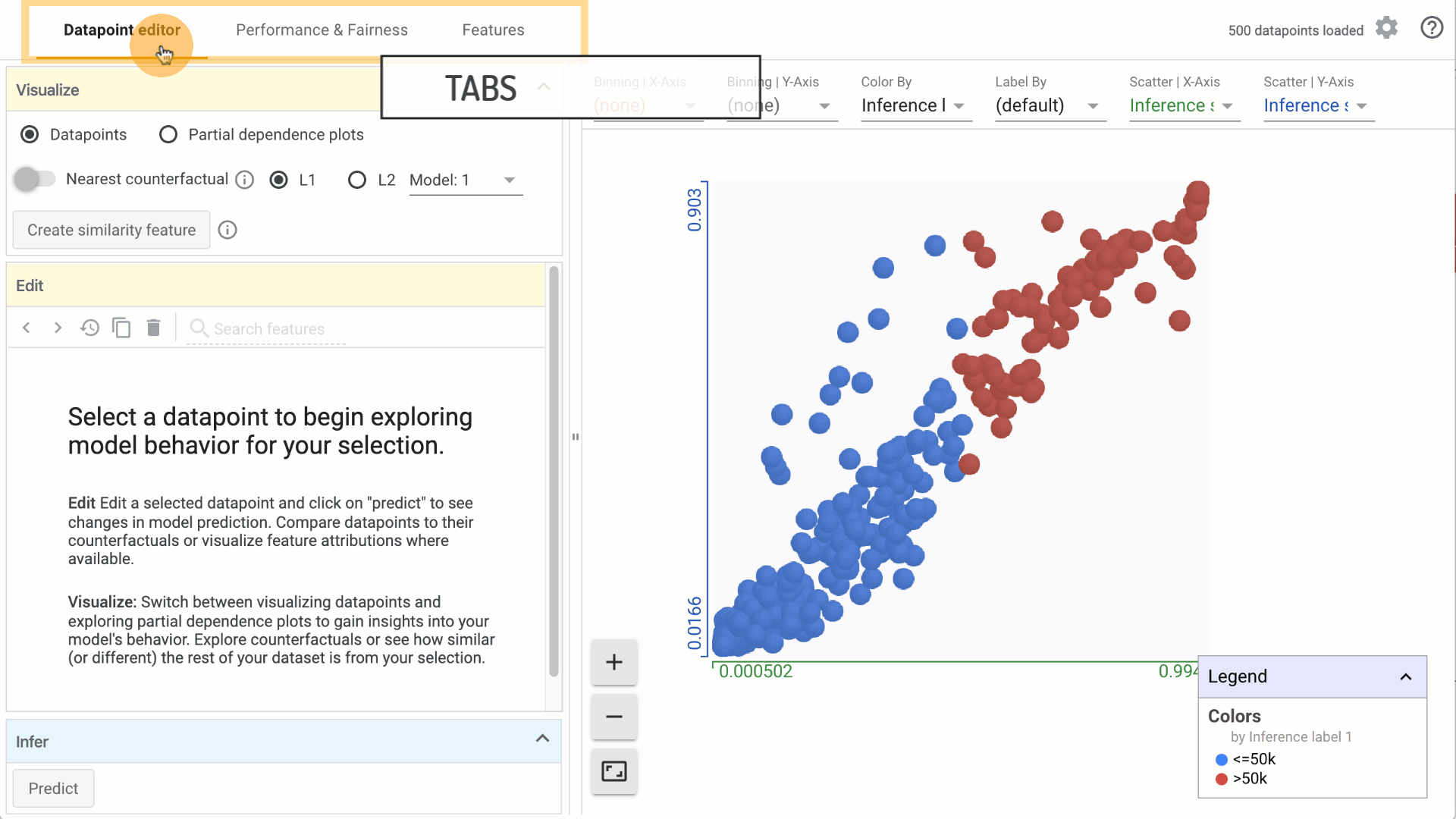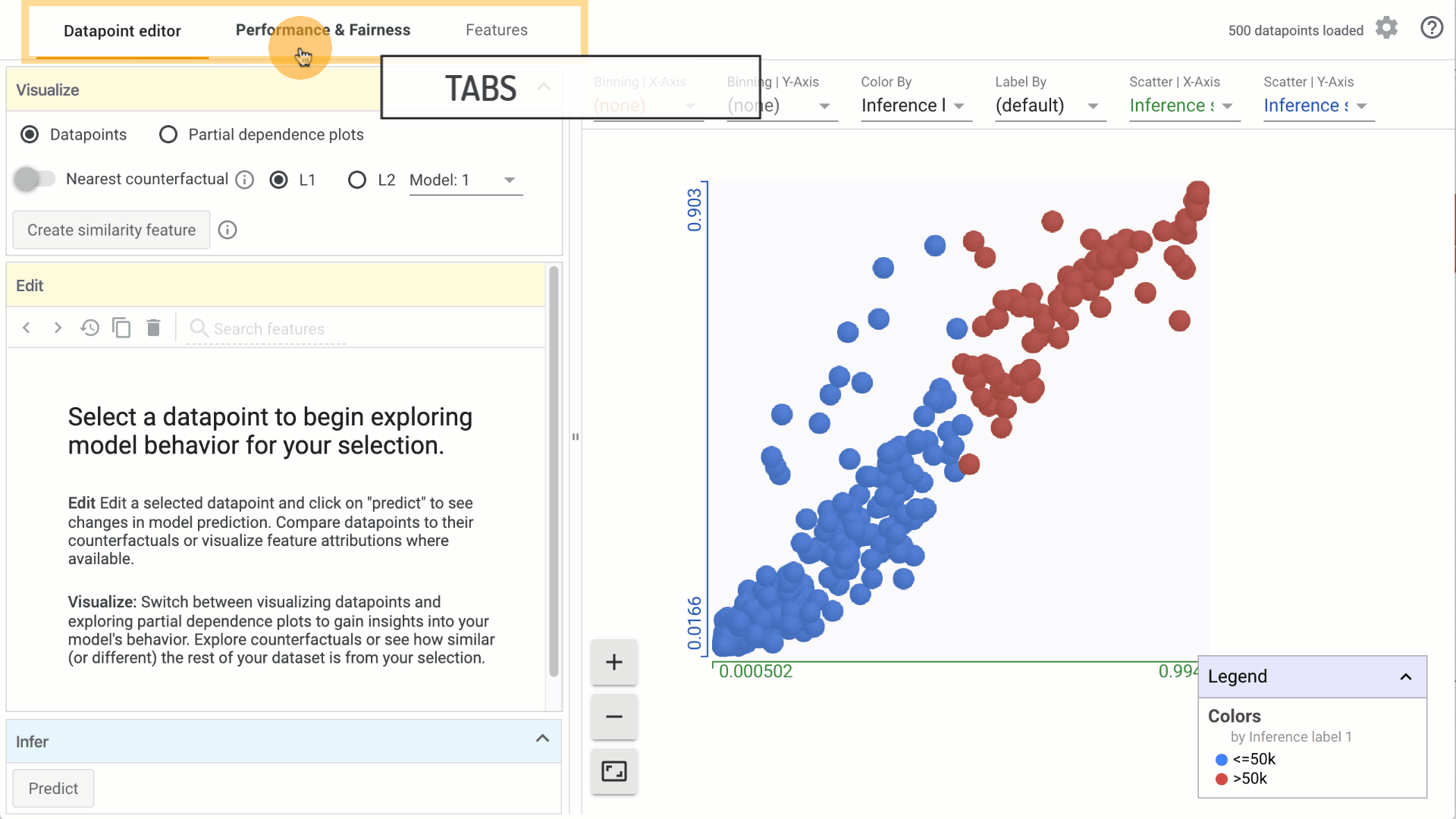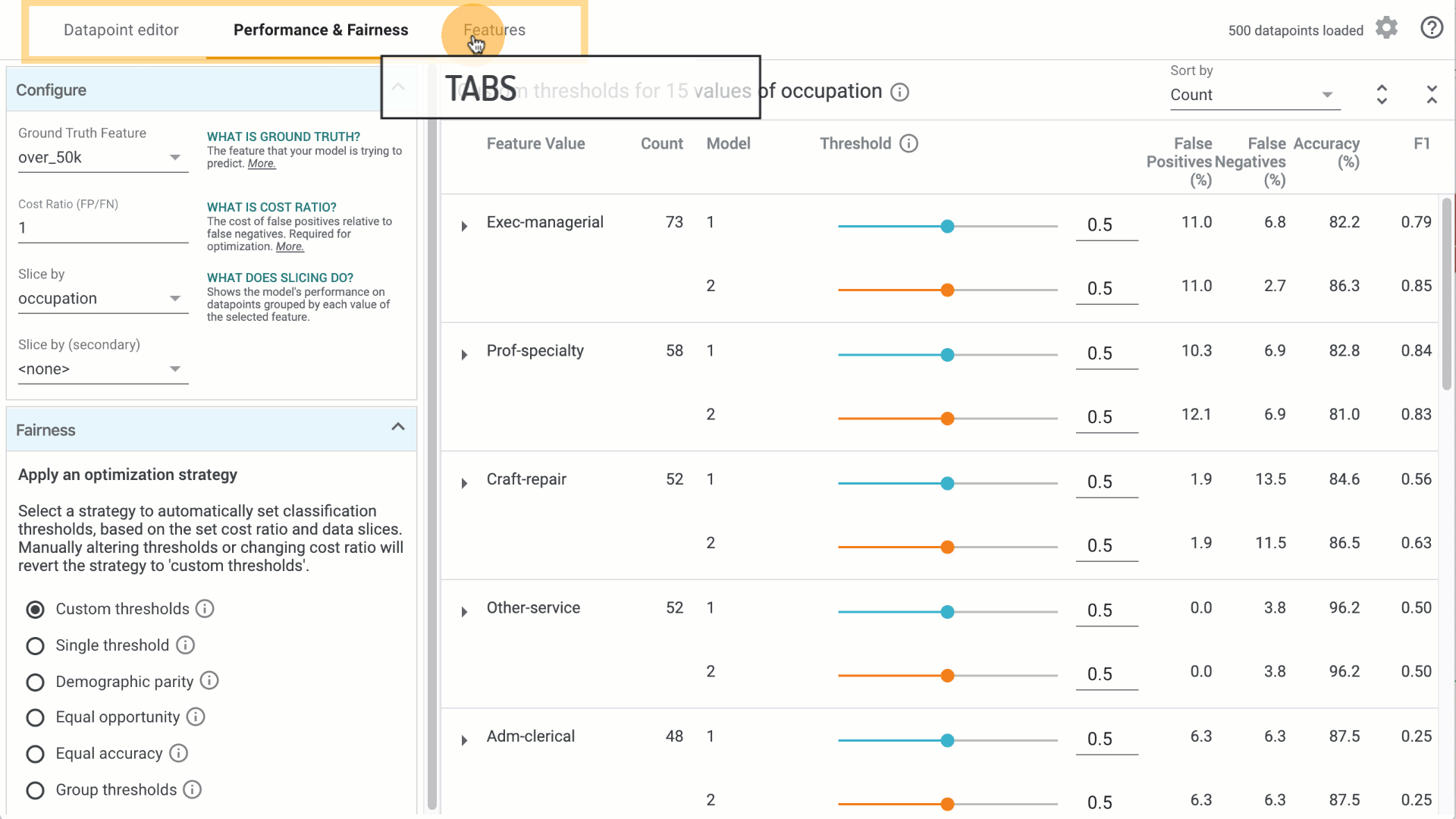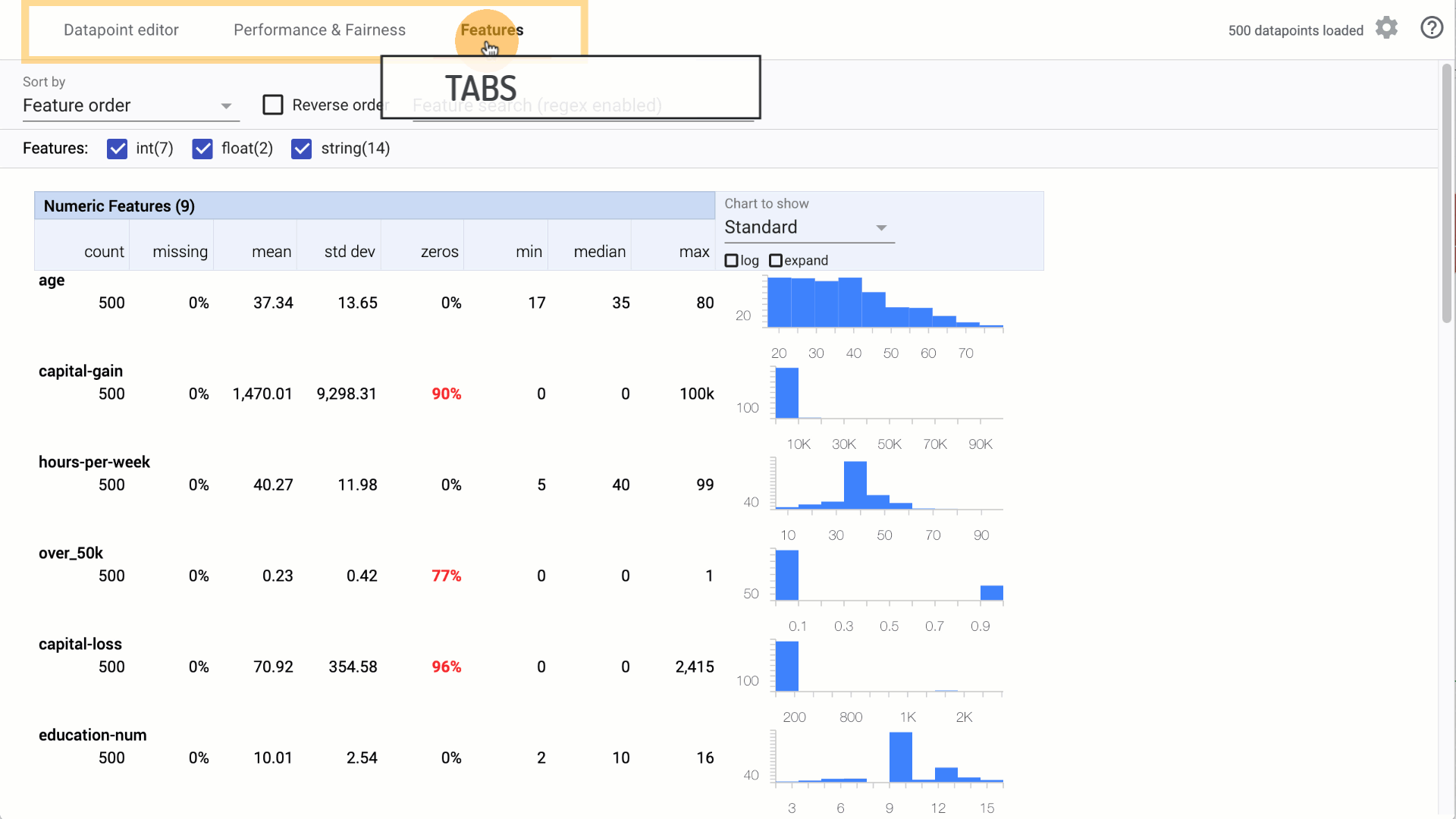
Once machine learning bias is detected, WIT can apply various fairness criteria to analyze the performance of the model (optimizing for group unawareness or equal opportunity).
2. IBM AI Fairness 360
AI Fairness 360 from IBM is another toolkit for detecting and removing bias from machine learning models. AI Fairness 360 is an open-source toolkit and includes more than 70 fairness metrics and 10 bias mitigation algorithms that can help you detect bias and remove it.
Bias mitigation algorithms include optimized preprocessing, re-weighting, prejudice remover regularizer, and others. Metrics include Euclidean and Manhattan distance, statistical parity difference, and many others.
The toolkit is designed to be open to permit researchers to add their own fairness metrics and migration algorithms.
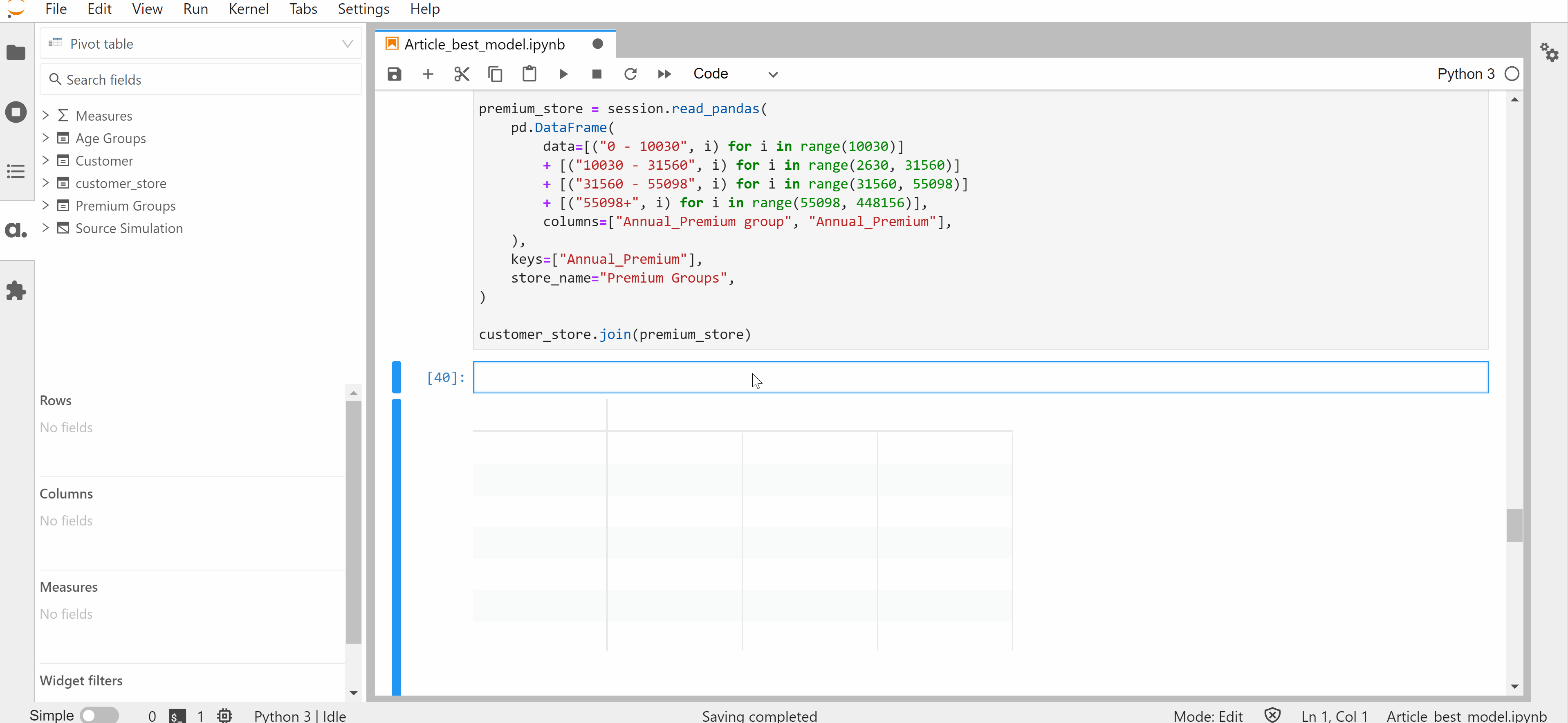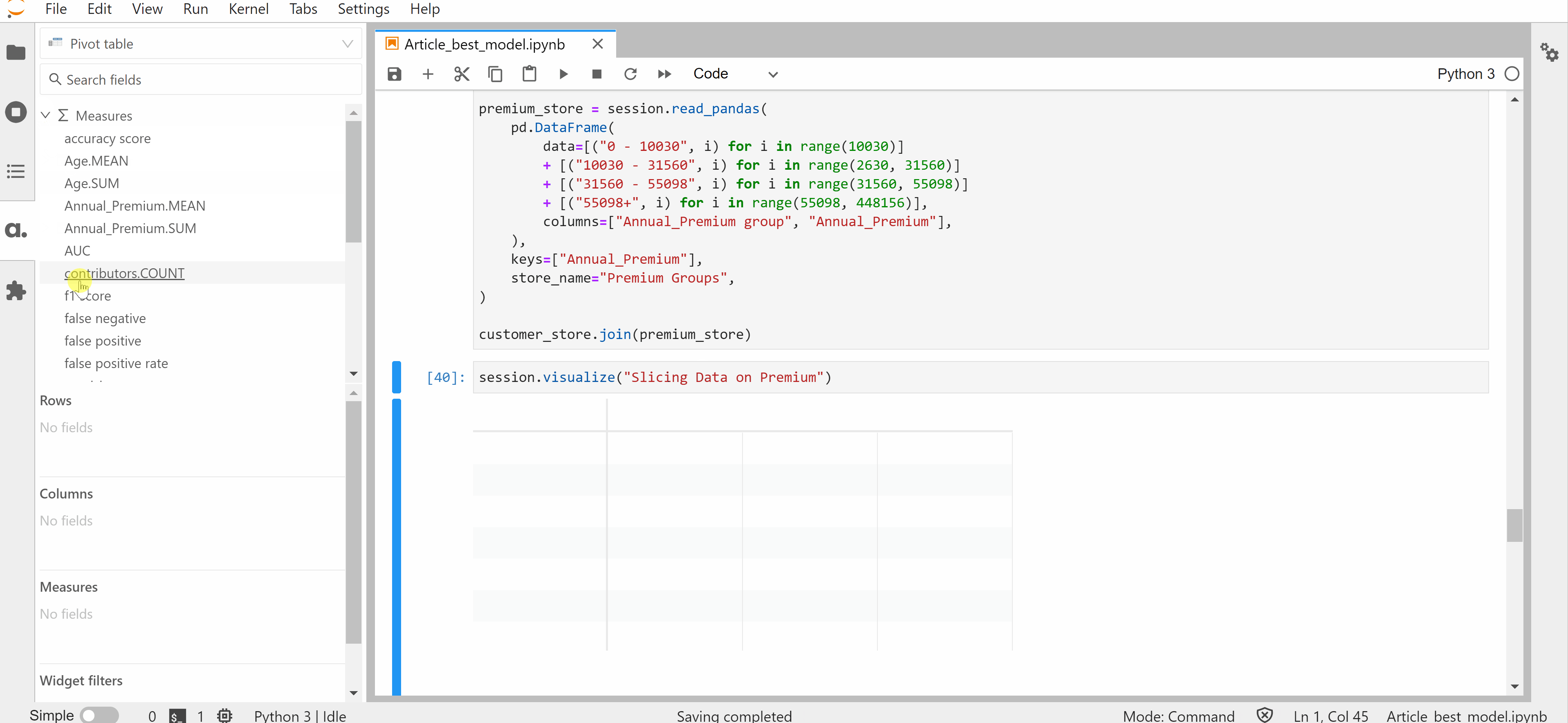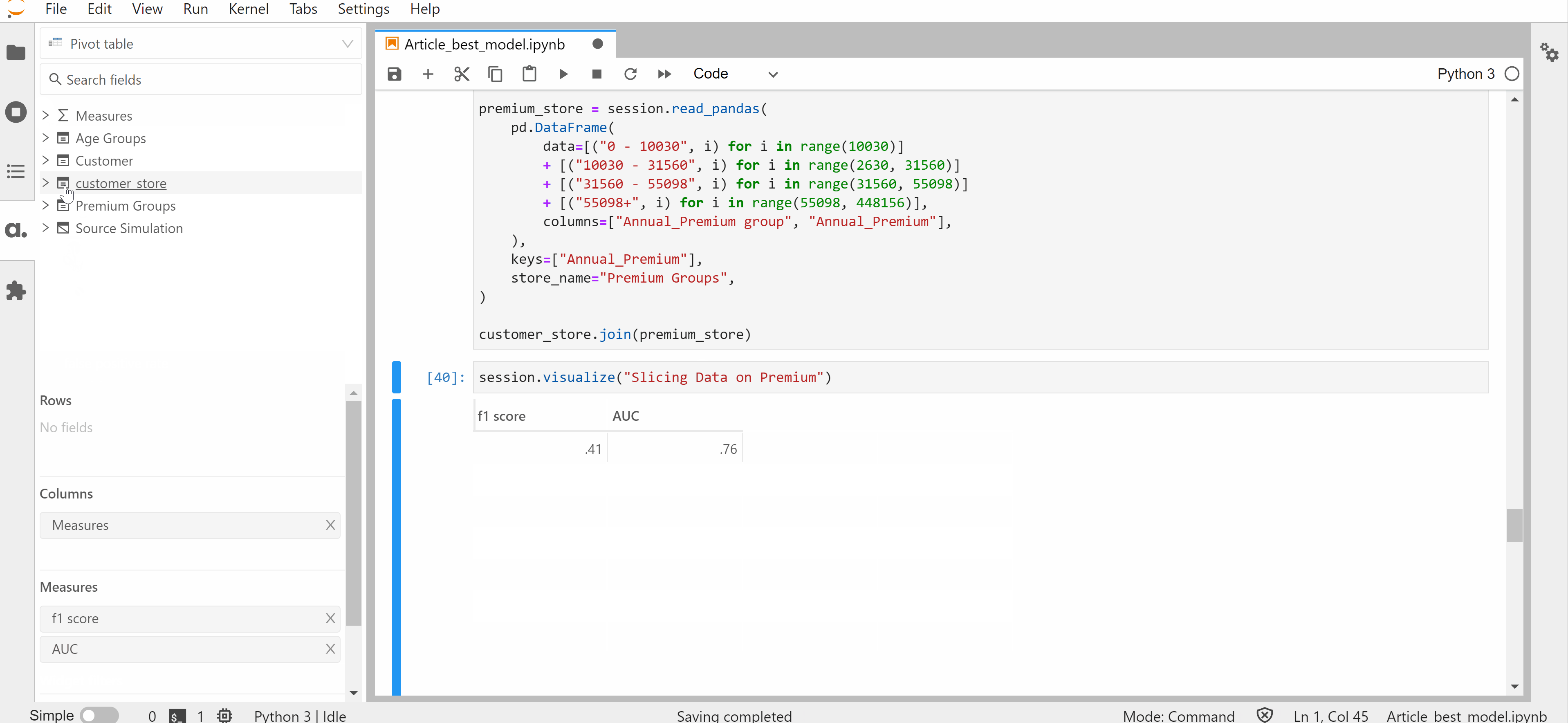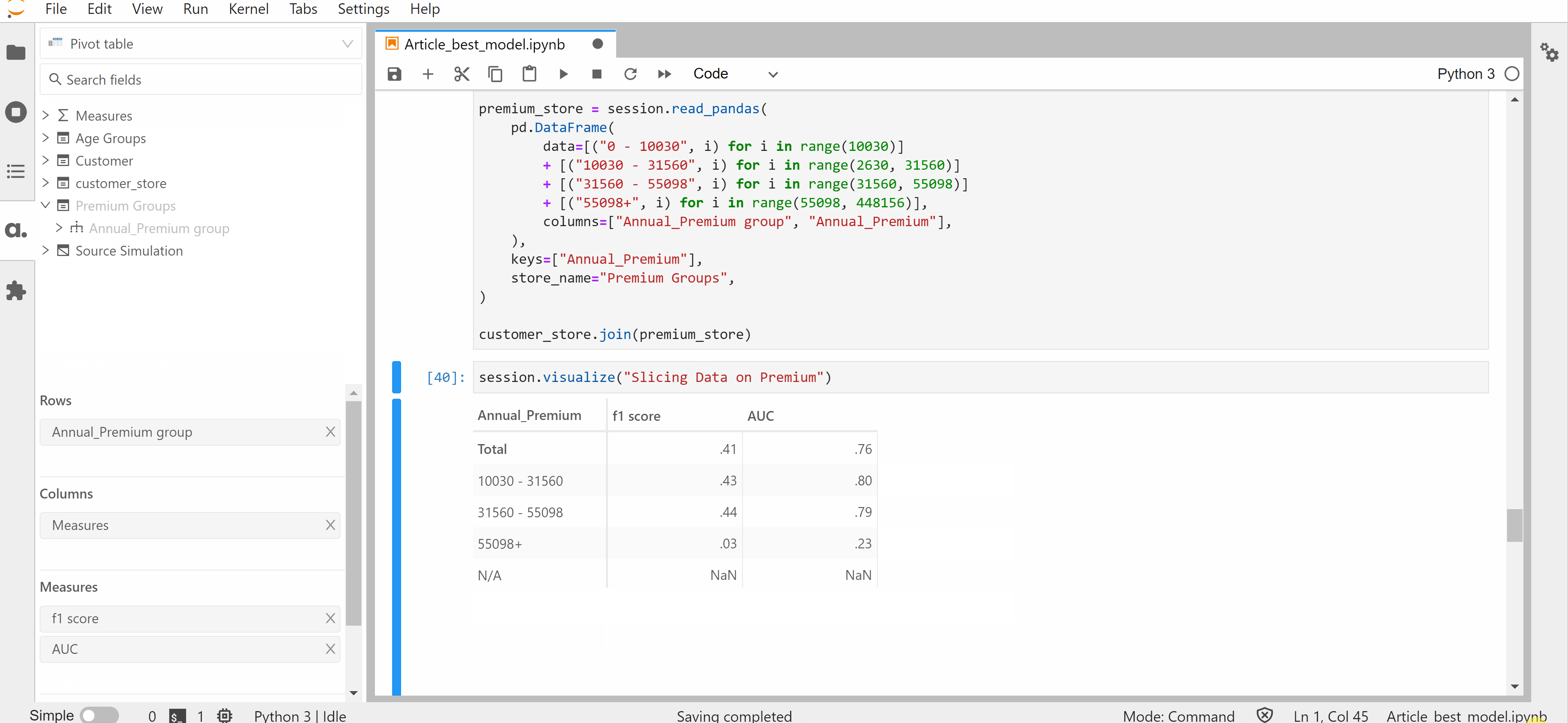
3. Subpopulation Analysis:
Subpopulation analysis is the procedure of considering just a target subpopulation from the whole dataset and calculating the model evaluation metrics for that population. This type of analysis can help and identify if the model favors or discriminates against a certain section of the population.
One way to perform subpopulation analysis is with pandas by filtering the target subpopulation as a new data frame and then calculating the metric in consideration for each of those dataframes. Another smarter way of doing sub-population analysis is by using Atoti to do sub-population analysis.
Atoti leverages the power of OLAP to slice and dice the model predictions. Hence, the benefits of using Atoti include:
- You can slice and dice the data as you want(make flexible data buckets)
- It enables you to create buckets on the fly
- You can calculate various metrics in a few clicks by leverage the power of the OLAP cubes
You can check out this notebook to get started with sub-population analysis in Atoti and see how it is better than the other methods.
4. debias-ml:
debias-ml is a practical, explainable and effective approach to reducing bias in machine learning algorithms.
DebiasML is a novel application of oversampling. Though popular for data imbalance problems, oversampling has not been adopted to address bias. When tested on the Adult UCI dataset, DebiasML outperforms Generative Adversarial Networks (GANs) on many dimensions. It results in a significantly higher F1 score (as much as +17%).
Conclusion:
Machine learning and Artificial Intelligence have shown great promise in self-driving cars, recognizing cancer in radiographs, and predicting whether a loan is safe or not(to name a few). But Machine learning and Artificial Intelligence come with their own benefits and challenges. One key challenge is the presence of bias in the classifications and predictions of machine learning.
These biases could actually do more bad than good. They have consequences based upon the decisions resulting from a machine learning model. Therefore, it’s important to understand how bias is introduced into machine learning models, how to test for it, and then how to remove it.
In this article, we discussed the various types of machine learning bias. Discussed the best practices to reduce machine learning bias. And finally enlisted some tools and techniques to detect and hence reduce machine learning bias.
Every week, we analyze the tweets in the data science community and publish a weekly report on top trending Twitter topics.
Check out the top trends and see how frequently the topic of machine learning bias makes it to the list of top Twitter topics!
For other such interesting use cases, check out our GitHub and Medium.

