

A Value-at-Risk benchmark where Atoti appears consistently five times faster than ClickHouse for this use case.
As data volumes and market complexity have increased, the financial services industry is ever more reliant on technologies that can quickly and seamlessly help them perform data analytics.
Performing calculations on hundreds of millions of rows of fast-moving data in real-time exceeds mainstream database capacities. Traditional databases cannot handle dynamic bucketing, non- linear, multi-step aggregations, statistics over simulations and time series in real time.
Array aggregation benchmark
Identifying technologies that can handle these tasks is difficult. Standard analytical benchmarks such as those found on the TPC do not support this.
This makes public benchmarks focused on fintech applications of this complexity extremely useful, and this is also why a recent blog post by Altinity on calculating Value-at-Risk (VaR) caught our eye. In that article, the ClickHouse database is compared to the AWS Redshift database for a VaR aggregation use case — that being non-linear aggregation of historical returns. In order to perform at interactive speed, that type of aggregation requires native support for array aggregation. Redshift is a popular general purpose data warehouse but does not support array aggregation and, therefore, cannot really be compared to more specialized technologies.
Atoti to the rescue
One of the biggest strengths of Atoti is its capability to perform aggregation very quickly on very large volumes of data. In their blog, Altinity invited some “friendly competition”. Let’s see if we can take up the challenge!
We ran the exact same benchmark using Atoti and found that it is in fact significantly faster.
- Atoti appears to aggregate consistently five times faster than ClickHouse.
- Conversely, Atoti appears to offer similar or better performance than ClickHouse while running on a much smaller (and less expensive) server.
In addition, Atoti offers advanced data modelling features including native array aggregation and multidimensional cubes. It does not require users to install, configure and manage a database like ClickHouse and it can work directly on the data like other popular Python libraries such as pandas.
Now let’s run the same benchmark referenced in the Altinity blog but with Atoti.
Aggregating data 5 times faster
We use the same data generator that produces a dataset with:
- 1,720,000 rows
- One array of 1000 historical returns per row
- About 7GB in size
We load it into Atoti and define the “VaR” measure. It’s all contained in this small notebook.
This is a very trivial way to calculate VaR. If you’re interested in more sophisticated analytics and what-if analysis please visit the public notebooks gallery.
Then we benchmark the four queries described in the reference blog post, reusing the VaR measure. Atoti is running on an AWS m5.8xlarge instance, in the same condition as the ClickHouse benchmark.
Q1
cube.query(m[“ValueAtRisk”], levels=[lvl[“str0”]])
Q2
cube.query(
m["ValueAtRisk"],
levels=[
lvl["str0"],
lvl["str1"],
lvl["int10"],
lvl["int11"],
lvl["dttime10"],
lvl["dttime11"],
],
)
Q3
cube.query(
m["ValueAtRisk"],
levels=[
lvl["str0"],
lvl["str1"],
lvl["str2"],
lvl["str3"],
lvl["int10"],
lvl["int11"],
lvl["int12"],
lvl["int13"],
lvl["dttime10"],
lvl["dttime11"],
lvl["dttime12"],
lvl["dttime13"],
],
)
Q4
cube.query(
m["PnL at index"],
levels=[lvl["str0"], lvl["Scenarios"]],
condition=(lvl["str1"] == "KzORBHFRuFFOQm"),
)
Here we set the queries in a notebook. Atoti also embeds an online user interface similar to Tableau and PowerBI, so in real life end-users would start analyzing VaR immediately from their browser, without having any query to write and without any additional software to deploy.

The Atoti engine is consistently five times faster for this VaR use case than the ClickHouse engine, according to the Altinity test.
Behind that performance is, in particular, special memory management, multicore processing, and query compilation. If you want to know more about the technology underpinning Atoti, you can watch this JavaOne presentation that discloses some of its secrets.
While a traditional database is sticky to its underlying hardware and persistent storage, Atoti as a Python library can be used on demand and anywhere, with a clean decoupling between storage and computation.
Faster but also cheaper in the cloud
Running the benchmark with Atoti on a smaller AWS instance: m5.xlarge (4 CPUs, 16GB RAM, 0.19$/hour)

Atoti is faster or equivalent to ClickHouse, while running on an eight-times less expensive server.
Running the benchmark with Atoti on the same m5.8xlarge instance than ClickHouse, but duplicating the dataset 6 times:
- 10,000,000 rows
- One array of 1000 historical returns per row
- About 42GB in size
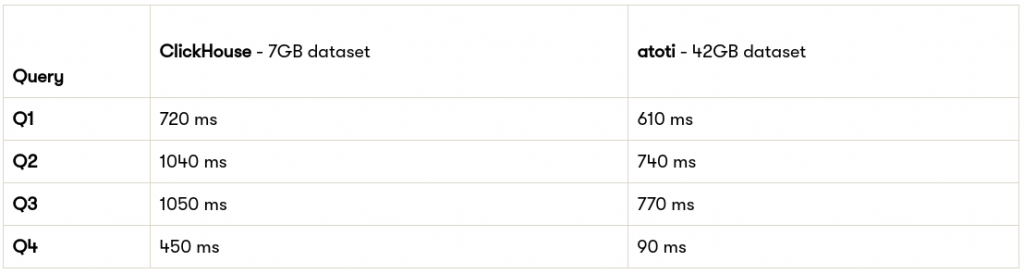
Atoti can process a dataset six times larger than ClickHouse in less time and for the same cost. If you are interested, you can easily try it for yourself by reproducing this test with Atoti.

