

I was inspired by an article about creating a Data Table using Data from Reddit and I was convinced that I could do much more with Atoti. Hence I started digging into the Reddit data and it piqued my interest so much, it became a trilogy! In this trilogy, I’m going to take you through:
- Data scraping
- NLP with spaCy
- Data exploration with Atoti
The article mentioned above was published quite some time ago, and Dash would probably have evolved way beyond. Nonetheless, my end game is to achieve the below dashboard with Atoti:

Check out how I could drill-down on different dimensions in the pivot table and interact with different data visualizations.
Let’s start with part 1 of my trilogy — data scraping Reddit! If you haven’t heard of Reddit before, do take a look! It has tremendous amounts of information on pretty much everything, classified under communities known as subreddits.
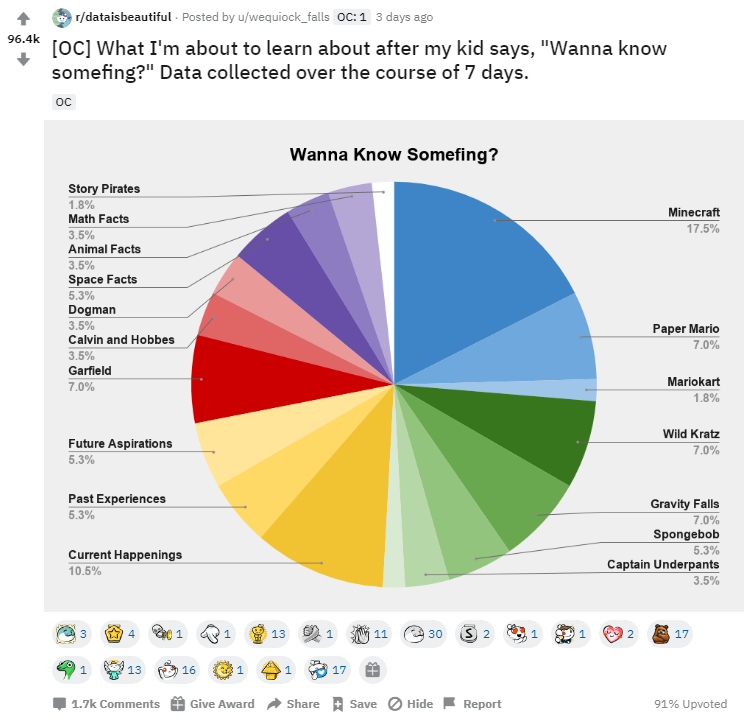
Being community driven, Reddit is a treasure trove of data that gives the trends and the opinions of the community towards various topics. Let’s take a look at how you can get your hands on these data.
PRAW — Python Reddit API Wrapper
PRAW is a Python package that I used to access Reddit’s API to scrape the subreddits that I’m interested in. For your information, you need to have a Reddit account in order to get an API key that is necessary for connection to Reddit.
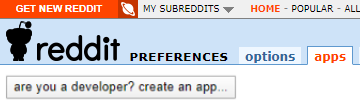
Click here to proceed to create an app by clicking on the button shown on the left.
Select “script” in order to obtain “refresh_tokens” and also use “https://localhost:8080” for the redirect uri as mentioned in the PRAW documentation.
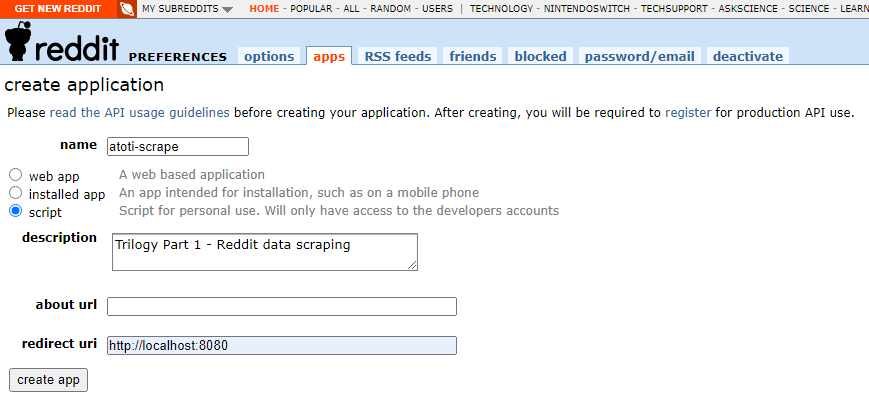
Click on the “create app” to get the API information needed for Reddit connectivity.
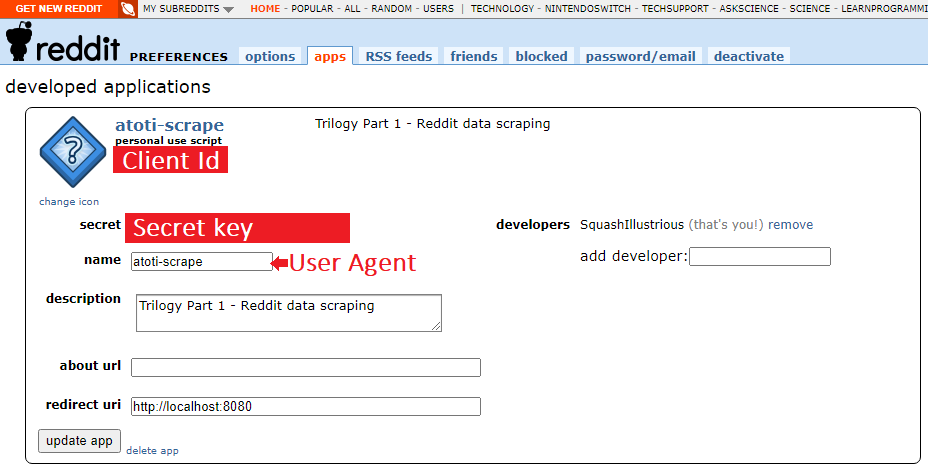
PRAW — Authentication
You can store the sensitive information highlighted in the screenshot above separately, and invoke properly when needed. To keep things simple, I’m showing how to apply these values to connect to Reddit. Pluck the 3 values into the code segment below:
!pip install praw
import praw
# create a reddit connection
reddit = praw.Reddit(
client_id=<client id>,
client_secret=<secret key>,
user_agent=<user agent>
)Accessing Subreddits
This is where the fun begins! Using the authorized Reddit instance, I can obtain a subreddit instance by passing the name of the subreddit as follows:
subreddit_ = reddit.subreddit("wallstreetbets")You can also combine multiple subreddits as follows:
subreddit_ = reddit.subreddit("wallstreetbets+politics+worldnews")Have a look at the Metrics for Reddit to know what Subreddits are available and which are the popular ones.
Accessing Submission instance from Subreddit instance
Reddit front is a listing class that represents the front page. Below is a summary of the front methods and what type of submissions they return:
- best — best items
- comments — most recent comments
- controversial — controversial submissions
- gilded — gilded items
- hot — hot items
- new — new items
- random_rising — random rising submissions
- rising — rising submissions
- top — top submissions
To access the attributes of the submission, iterate through the list returned by the front method.
In my case, I appended the attributes of the submission to a list so that I can convert it into Pandas dataframe later on:
import pandas as pd
# list for df conversion
_posts = []
# return 100 new posts from wallstreetbets
new_bets = reddit.subreddit("wallstreetbets").new(limit=100)
# return the important attributes
for post in new_bets:
_posts.append(
[
post.id,
post.author,
post.title,
post.score,
post.num_comments,
post.selftext,
post.created,
post.pinned,
post.total_awards_received,
]
)
# create a dataframe
_posts = pd.DataFrame(
_posts,
columns=[
"id",
"author",
"title",
"score",
"comments",
"post",
"created",
"pinned",
"total awards",
],
)
_posts["created"] = pd.to_datetime(_posts["created"], unit="s")
_posts["created date"] = pd.to_datetime(_posts["created"], unit="s").dt.date
_posts["created time"] = pd.to_datetime(_posts["created"], unit="s").dt.timeNotice that I used the front method “new” to retrieve the latest 100 submission (set using the limit parameter) from the subreddit Wallstreetbets.

Voila! Now I have the data from Reddit and I’m ready to try out Natural Language Processing (NLP) with it! Check out part 2 of my trilogy — NLP with spaCy!

