

Follow along as we extract topics from Twitter data using a revisited version of BERTopic, a library based on Sentence BERT.
This article presents how we extract the most discussed topics by data science & AI influencers on Twitter. The topic modeling approach described here allows us to perform such an analysis on text gathered from the previous week’s tweets by the influencers.
The objective is to discover and share constantly interesting content on artificial intelligence, machine learning, and deep learning, e.g., articles, research papers, reference books, tools, etc.
To achieve this, we leverage the power of BERT through the use of BERTopic, a topic modeling Python library, which we revisited slightly by implementing two additional features to fit our use case.
Overview
We will be talking about:
- What Is BERTopic?
- The Need To Modify BERTopic?
- BERTopic Enhancement
We present BERTopic and detail our custom implementation in the following sections.
What Is BERTopic?
BERTopic is a BERT based topic modeling technique that leverages:
- Sentence Transformers, to obtain a robust semantic representation of the texts
- HDBSCAN, to create dense and relevant clusters
- Class-based TF-IDF (c-TF-IDF) to allow easy interpretable topics whilst keeping important words in the topics descriptions
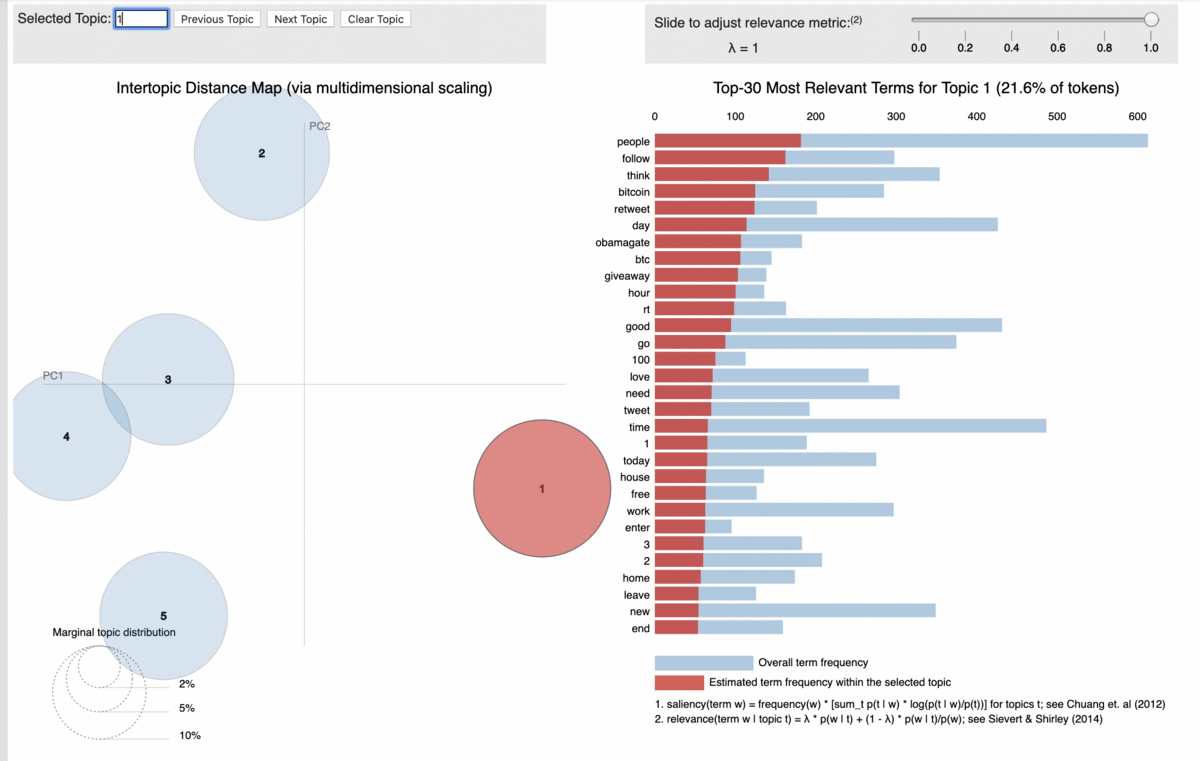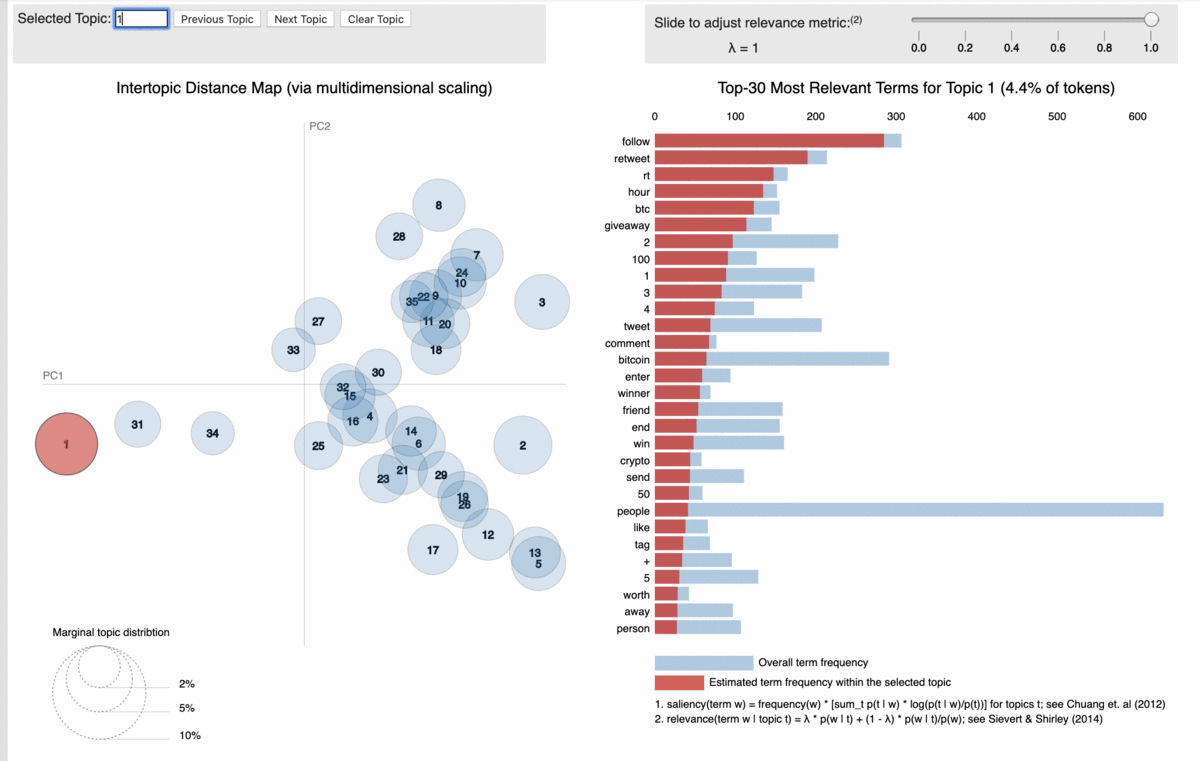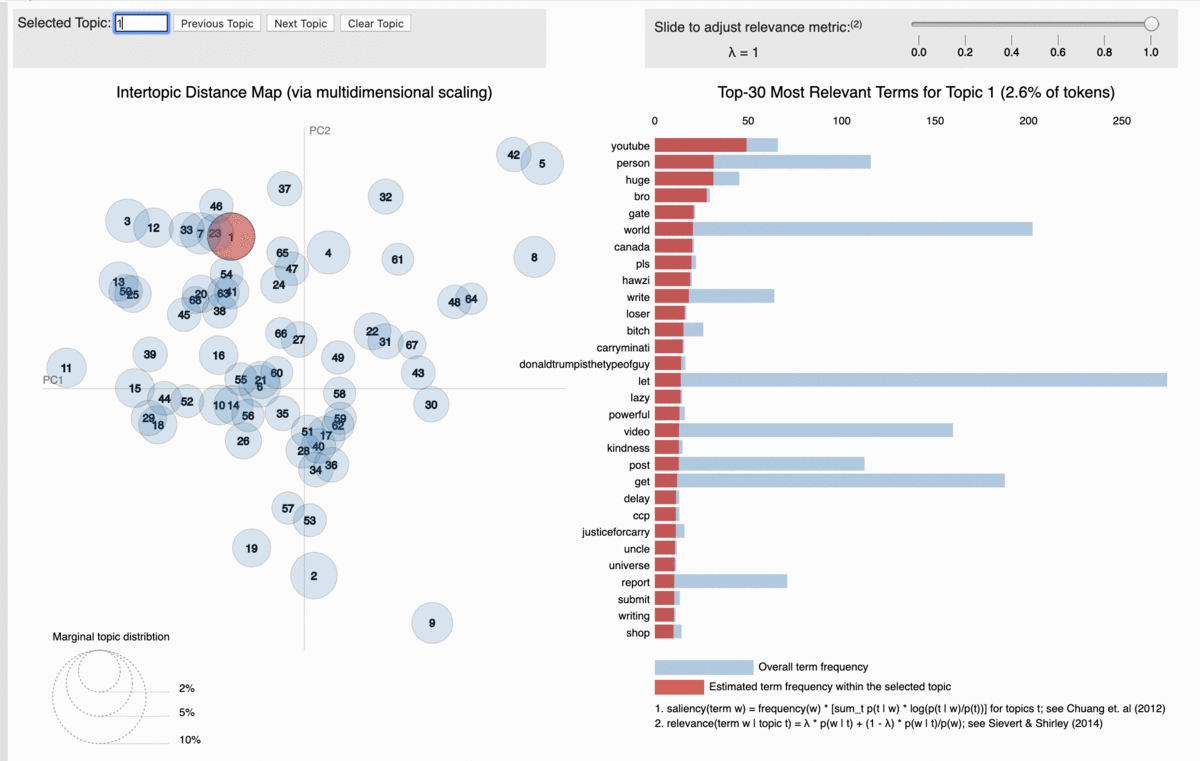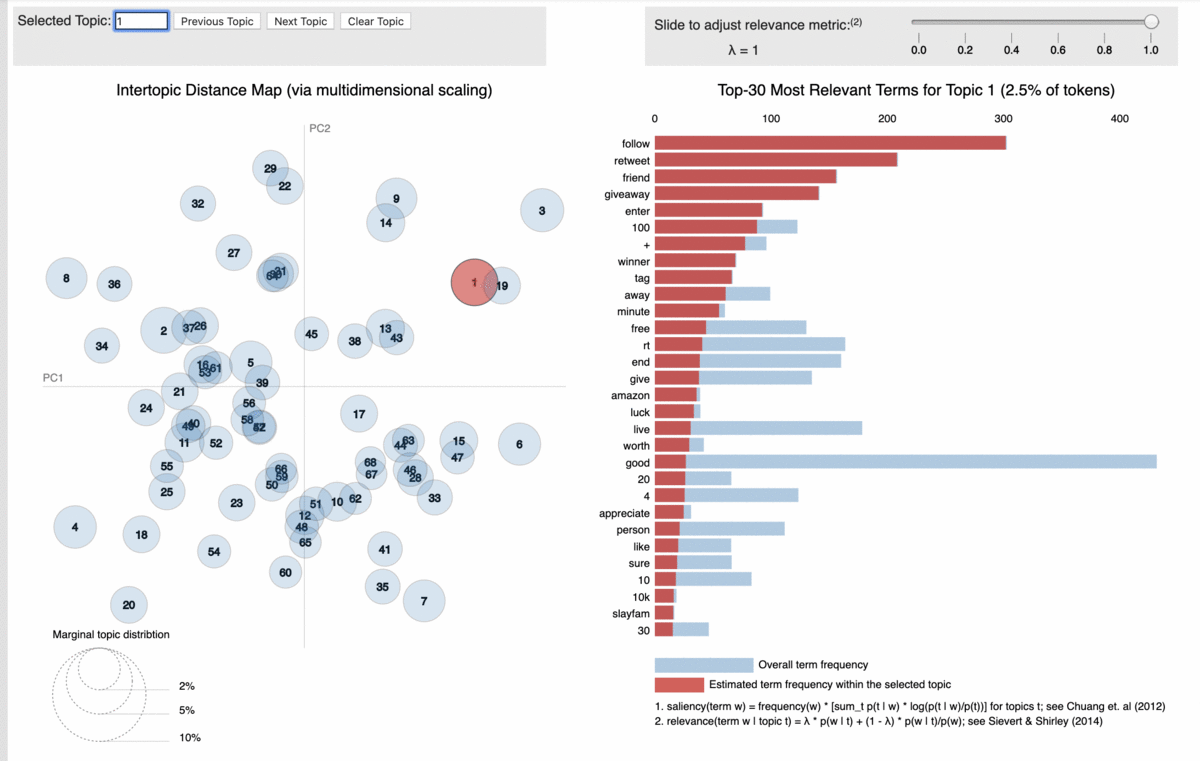
For exhaustive details on how to use BERTopic, please, refer to this article.
The Need For Additional Features
To fit our use case, we slightly revisited this Sentence BERT based library to be able to:
- Merge topics having a similarity above a user-defined threshold
- Extract the most relevant documents associated with any given topic
The above features are missing from the original library.
For topics merging, BERTopic only proposes the following:
- At creation time, it automatically merges the topics with a (cosine) similarity above 0.915 (value hard-coded in the instantiation of the model object);
- At any time, it allows you to fix the number of topics to be created by specifying it explicitly via the appropriated parameter of the model. In that case, if the original number is higher than the parameter value specified, this will cause the former to be reduced iteratively by merging the least frequent topic with the most similar one until reaching this last.
Consequently, we decided to add the above two features to the original package, which we describe in the following section.
BERTopic Enhancement
This section presents how we modify the BERTopic package to make it more flexible in defining a custom similarity threshold to merge topics and extract the most relevant documents (representatives) associated with any topic.
Apply a user-defined similarity threshold for topics merging
The following codes show how to perform topic extraction using our custom BERTopic:
# Load sentence transformer model
sentence_model = SentenceTransformer("roberta-base-nli-stsb-mean-tokens")
# Create documents embeddings
embeddings = sentence_model.encode(docs, show_progress_bar=False)
# Define UMAP model to reduce embeddings dimension
umap_model = umap.UMAP(n_neighbors=15,
n_components=10,
min_dist=0.0,
metric='cosine',
low_memory=False)
# Define HDBSCAN model to perform documents clustering
hdbscan_model = hdbscan.HDBSCAN(min_cluster_size=10,
min_samples=1,
metric='euclidean',
cluster_selection_method='eom',
prediction_data=True)
In the above code snippet, we define:
- The Sentence BERT model, at line 2;
- Which we use to embed the documents, at line 5 (you may choose a different BERT based model that best fit your use case here);
- The dimension reduction model, at line 8, using UMAP, a non-linear dimension reduction technique;
- The clusterer model using HDBSCAN to group the tweets into clusters
Then, we extract the topics as follows:
# Create BERTopic model
topic_model = BERTopic(top_n_words=20,
n_gram_range=(1,2),
calculate_probabilities=True,
umap_model= umap_model,
hdbscan_model=hdbscan_model,
similarity_threshold_merging=0.5,
verbose=True)
# Train model, extract topics and probabilities
topics, probabilities = topic_model.fit_transform(docs, embeddings)
At lines 2–8 here above, we create a topic model using our new custom parameter named similarity_threshold_merging (line 7) that allows the user to merge the topics with a cosine similarity above the provided value (threshold).
In fact, BERTopic provides a function allowing to calculate the cosine similarity between two topics based on their c-TF-IDF matrices (see this link for an explanation on c-TF-IDF). It also provides a function called _auto_reduce_topics() that proceeds to topics merging.
We modify this function by adding a condition for topics merging which:
- Uses the value of the similarity_threshold_merging parameter if provided;
- Alternatively, it uses the default threshold of 0.915 from the original BERTopic class.
In line 11, we fit the topic model on the data comprising the tweets texts and their corresponding embeddings. Then, we obtain:
- topics, a vector showing the predicted topic for each tweet;
- probabilities, an array of shape (num_documents, num_topics), which is obtained thanks to soft clustering, a feature used in HDBSCAN. Each row index gives the probabilities of the corresponding tweet of being part of the different topics
Now, we have our topics extracted from the Twitter data!
Extract the most relevant documents for any given topic
Once the topics have been extracted, it is always interesting to analyze them, e.g., by getting:
- The keywords that describe them (e.g., the top-10 words)
- The documents that best illustrate them (representatives)
Here, we will focus on the latter point as this feature is not provided in the original BERTopic.
Quick reminder: For BERTopic, a topic consists of a cluster of documents.
As shown in the preceding part, HDBSCAN provides probabilities along with the cluster’s predictions. Each row index of the probabilities array gives the corresponding tweet probabilities of being a member of the different clusters. So, we could be tempted to consider the representatives of a given cluster as the tweets having the higher probabilities of being part of it (rows with the highest values in the corresponding column of the probabilities array), which sounds good.
Unfortunately, soft clustering is still an experimental feature with its fair share of open issues that are available in the HDBSCAN repository. So, in some cases, considering the returned probabilities could not be ideal.
Consequently, we decide to define the most relevant tweets associated with a given topic as the core points of the corresponding cluster.
In the HDBSCAN documentation, these points, also called exemplars, are considered to be at the “heart” of the cluster “around which the ultimate cluster forms” using soft clustering.
Ultimately, we will consider only exemplars tweets to illustrate the topics.
To extract the clusters’ exemplars, we provide the following function that we get from the HDBSCAN official documentation.
def get_most_relevant_documents(cluster_id, condensed_tree):
assert cluster_id > -1, "The topic's label should be greater than -1!"
raw_tree = condensed_tree._raw_tree
# Just the cluster elements of the tree, excluding singleton points
cluster_tree = raw_tree[raw_tree['child_size'] > 1]
# Get the leaf cluster nodes under the cluster we are considering
leaves = hdbscan.plots._recurse_leaf_dfs(cluster_tree, cluster_id)
# Now collect up the last remaining points of each leaf cluster (the heart of the leaf)
result = np.array([])
for leaf in leaves:
max_lambda = raw_tree['lambda_val'][raw_tree['parent'] == leaf].max()
points = raw_tree['child'][(raw_tree['parent'] == leaf) & (raw_tree['lambda_val'] == max_lambda)]
result = np.hstack((result, points))
return result.astype(np.int)
A simplified explanation of what is done in this function follows:
- From the condensed tree with all the points (tweets) at line 5, we get all the clusters at line 8;
- From these clusters, we isolate the one we are looking for exemplars, and we get all its sub-clusters (leaf cluster nodes) at line 11;
- Inside each of these sub-clusters, we select the most persistent points (with the highest value of lambda) at lines 17–19;
- Finally, we return these last points as the cluster’s exemplars
We use this function to extract exemplars here below:
# Get the clusterer model, the clusters' tree and the clusters (topics ids) clusterer = topic_model.hdbscan_model tree = clusterer.condensed_tree_ clusters = tree._select_clusters() # Get the ids of the most relevant documents (exemplars) associated with the topic at index idx c_exemplars = topic_model.get_most_relevant_documents(clusters[idx], tree)
In the codes here above:
- We get the clusterer model with its associated tree and clusters within it, at lines 2–4;
- We extract the exemplars points within the considered cluster, at line 7, using the get_most_relevant_documents() function that we have added to the original implementation. It gives a NumPy array containing the indexes of the exemplars documents.
Finally, we get the representatives of the considered topic.
You can find the complete codes of our enhanced BERTopic library in this Github repository.
Et voilà!
References
Maarten Grootendorst. (October 5, 2020). Topic Modeling with BERT.
Sentence Transformers. SentenceTransformers Documentation.
UMAP. Uniform Manifold Approximation and Projection for Dimension Reduction.
HDBSCAN. The hdbscan Clustering Library.
Arzucan Ozgur & Tunga Gungor. (January 2005). Text categorization with class-based and corpus-based keyword selection.

