

From the default log to how to configure additional logging
Application logs are extremely important in any system! Most commonly, they are used to troubleshoot any issue that users may encounter while using an application. For instance, developers use them for debugging and the production support crew uses them to investigate outages.
Not just that, in production, they are used to monitor an application’s performance and health. For instance, monitoring tools can pick up certain keywords to identify events such as “server down” or “system out of memory”. It can also serve as an audit trail to track user activity and system events.
Therefore we want to be sure that we log enough details to support these activities, but not overly so to the extent of leaking sensitive information such as user details or client profiles!
Atoti server log access
By default, the Atoti logs are written to the session directory under $ATOTI_HOME which is defaulted to $HOME/.atoti.
Use atoti.session.logs_path to access the log folder.
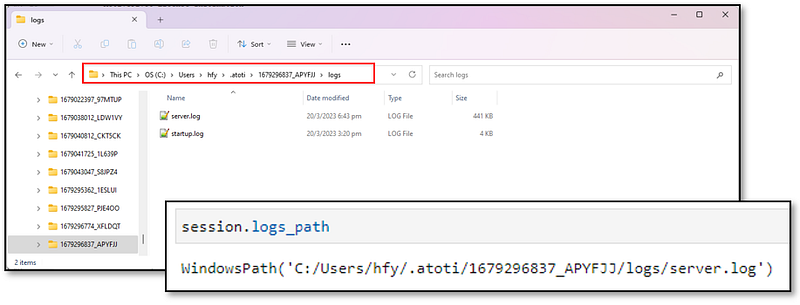
Logs get rolled and compressed if they grow beyond 10MB. A maximum history of 7 days is maintained. We can, however, overwrite this as we will see later on in this article.
As we see in the screen capture above, there are two logs generated in the logs folder:
- startup.log
- server.log
Let’s understand what we can do with each of them.
Startup log
As the name suggests, startup.log is generated at the startup of the Atoti server. It does not contain much interesting information except licensing details, e.g.:
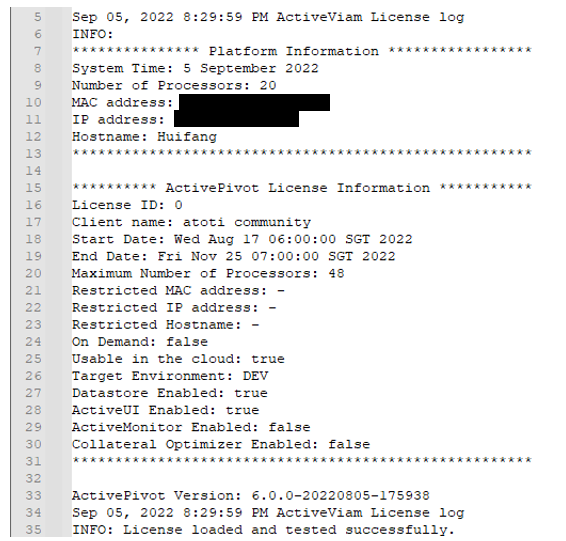
Server log
This is what we are after most of the time, whether we are troubleshooting our exceptions or reporting an issue in Atoti’s GitHub repository.
Troubleshooting common errors
Data type error
We know to look at the log when the pink banner below prompts us to:
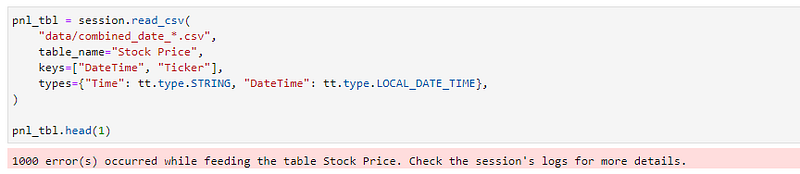
Prompt troubleshooting using the log saves us from a wild goose chase. The below log clearly indicates that the date parsing of the char sequence “2023–03–10 13:59:00” failed. It also explained the expected date pattern is “yyyy-MM-dd[[][‘T’]HH:mm[:ss][.SSS]]”.
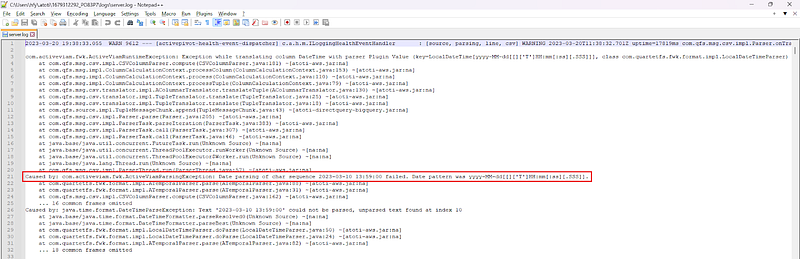
It’s easy to fix it once we know the error: our LocalDateTime object is expecting timezone and milliseconds information but our values only are only up to the seconds. A quick fix is to set the date format with date_patterns as shown below:
pnl_tbl = session.read_csv(
"data/combined_date_*.csv",
table_name="Stock Price",
keys=["DateTime", "Ticker"],
types={"Time": tt.type.STRING, "DateTime": tt.type.LOCAL_DATE_TIME},
date_patterns={"DateTime": "yyyy-MM-dd HH:mm:ss"}
)
Data source error
Sometimes, we can’t help but correct the issue from the source. At least, the log clearly shows we have an invalid day value for the date “2023–03–32 10:43:00”.
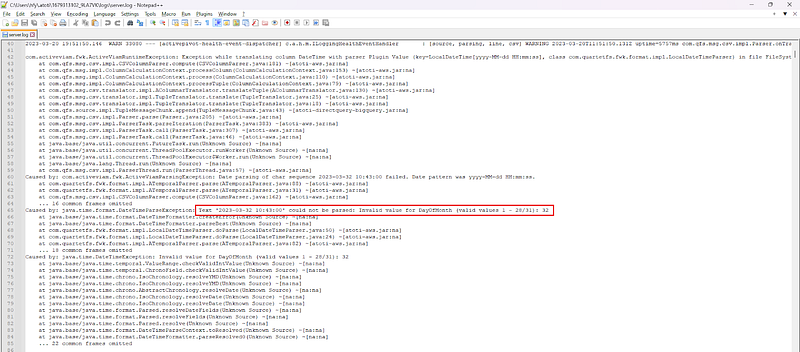
API usage error
It may look intimidating when we see a big blob of pink with chunks of exception. But it’s really not that serious — it’s a KeyError for the level Hour.
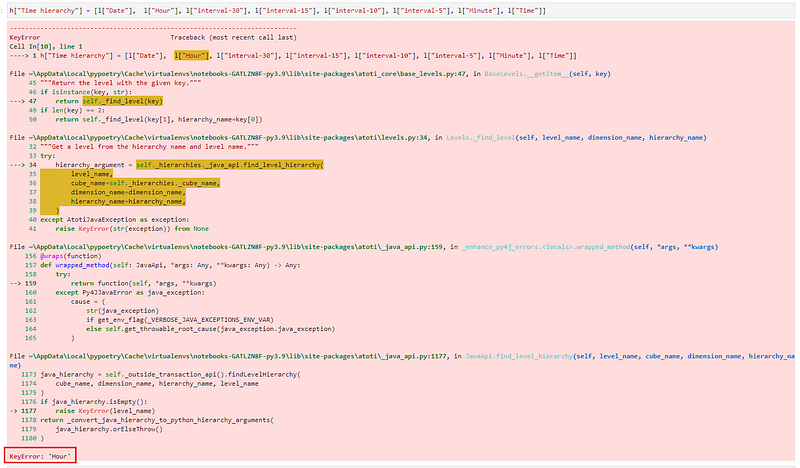
Stacktraces that are thrown within the Jupyter notebook may not be reflected in the server.log.
What it really means is that “Hour” is not found as a key in the cube’s level map. So, we start troubleshooting by looking at our cube level:
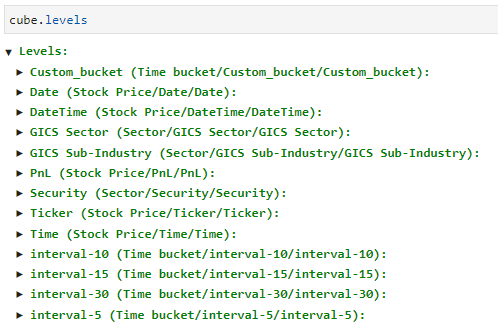
Indeed it’s not there. It requires a little detective work here… We need to be aware that columns are automatically created into single-level hierarchies only when it’s non-numerical. So, if it’s not appearing as level as expected, it can only mean that it’s created as a measure. The cube schema proves the point.
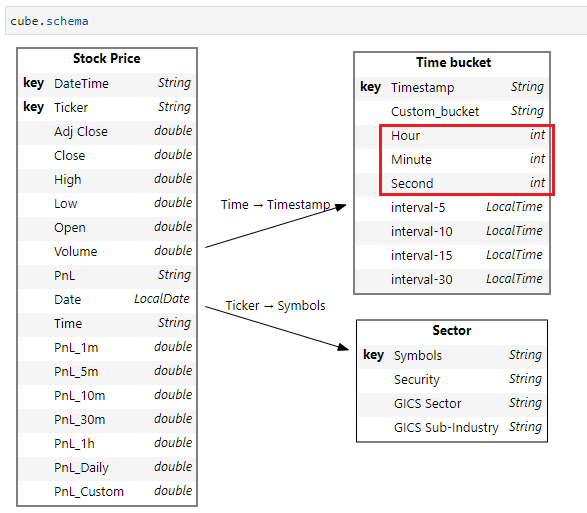
One fix for this is simply to use the table name instead of the level to create the multilevel hierarchy.
h["Time hierarchy"] = [
l["Date"],
time_bucket["Hour"],
l["interval-30"],
l["interval-15"],
l["interval-10"],
l["interval-5"],
time_bucket["Minute"],
l["Time"],
]
Health monitoring and audit tracking
Memory usage
We may see chunks of loggings as shown below:

This is the memory usage logged by the Atoti server health monitor.
Heap[used=225 MiB 200 KiB (236134400) (+(0)), committed=336 MiB (352321536) (+(0)), max=7 GiB 944 MiB (8506048512) (+(0))]
Direct[used=139 MiB 808 KiB (146579524) (+(0)), count=1034 (+0), max=7 GiB 944 MiB (8506048512) (+(0))]
We can see that the server stabilized(i.e. no more data loading), the heap size used is about 225 MB and the direct memory used is 139 MB. It totals up to 354 MB of memory used.
This is very useful when it comes to capacity planning, as we can use it to project the amount of memory consumption required for a given volume of data over a period of time. As a start, we recommend at least a 2 times memory buffer of what is projected. Thereafter, we can proceed to tune the performance based on individual projects’ needs.
Data loaded
Depending on the type of mechanism used for data loading, the log will also reflect the number of records that are available
in the source versus the number of records that are successfully loaded.

Log destination customization
With atoti.LoggingConfig, we can define a location other than the default to store our logs. It can be a path such as C:/atoti/server.log or sys.stdout to stream it to the Python process’ standard output:
import atoti as tt
logging_config = tt.LoggingConfig(destination="C:/atoti/server.log")
session = tt.Session(logging=logging_config)
Additional logging
There are instances where we require additional logging while setting up our application pipelines, e.g. when we are configuring authentication to an authentication provider such as LDAP.
The underlying Atoti server uses the Spring Framework. Knowing this allows us to configure additional logging during the instantiation of our Atoti session. For instance, under the java_options parameter, we add in the logging parameters as shown below:
session = tt.Session(
port=10011,
authentication=get_auth_mode(),
user_content_storage="./content",
java_options=[
"-Dlogging.level.org.springframework.security=DEBUG",
"-Dlogging.level.org.springframework.ldap=DEBUG",
],
)
“-Dlogging.level.org.springframework.security=DEBUG” returns the logs from Spring security and “-Dlogging.level.org.springframework.ldap=DEBUG” returns the logs from the LDAP package.
Log all exceptions
One last useful tip, we can set the environment variable ATOTI_VERBOSE_JAVA_EXCEPTIONS to True to capture all the exceptions in the log.
import os
os.environ["ATOTI_VERBOSE_JAVA_EXCEPTIONS"] = "True"
Summing it all up
This article is just the tip of the iceberg when it comes to what we track in the Atoti server logs. We hope it gives you directions on how to start troubleshooting any issues you encounter. And if you’re lost, you can always open a ticket with us on GitHub. Just don’t forget to add in the logs 😉

