Machines are learning our biases and she is on a mission to fix it. Plus, how Hollywood has been feeding the problem.
I had the opportunity to meet Ayodele in a bit of a fan-girl moment. As someone passionate about intended and unintended bias in technology, I knew from her profile she was an expert from whom I (and everyone) could learn. And lucky for us, she is a natural born mentor.

Ayodele Odubela is a former marketing specialist who went back to school to study data science. Along the way, she awakened to the myriad biases inherent in the models she was building and the projects as they were defined. She walked me through some of these moments, as well as how she believes these issues can be resolved — from making data science more accessible to underrepresented groups to accountability within big data firms.
This article is part one of a two part write up. Part one will focus on dismantling bias, while part two will focus on her work as a mentor and data science career coach.
[. . .] machine learning tends to codify [racism, sexism, ableism, ageism, nationalism] inside of models.
Hetal: Bias is a word that’s used a lot in data science and machine learning. But it’s a weird word: it can be a statistics term, and it could mean prejudicial point of view. When you’re talking about ethical AI and bias, which is it?
Ayodele: First, I’m really talking about societal biases. So I think that’s hard. We have to almost ignore the technical statistical definition. I think to be more specific, talking about all the isms, so specifically, racism, sexism, ableism, ageism, nationalism, and a couple others like xenophobia. When specifically talking about bias, How machine learning tends to codify all of these things that I mentioned, inside of models.

Hetal: How do machine learning models encode these biases?
Ayodele: I think it’s two-sided. One half is the engineer population — when products are created by human beings, it’s difficult to separate the human bias. That goes along with human error when we’re actually creating models. This can be: model choice or incorrect model choice, not enough understanding about historical context, ability to look at a data set and not be able to clean the data properly, or not understanding which groups are likely to face harm based on models created on certain kinds of data.
The other half comes from the data itself. With the internet, we’ve seen so much data created but it’s also been a massive playground for bias data sets: things like when you Google “doctor,” if we scrape all of that data and create a model, despite the fact that the model has no understanding of gender or society, it will still make more associations between images of men and doctors than women.
Hetal: You attended a data for Black Lives conference. Where would you say in your journey of tackling ethics in AI intersected with Data for Black Lives?
Ayodele: I would say it was part of the kickoff of my career focus on these issues. I started my career in marketing, went back to school for a master’s in data science. I had one ethics course but it wasn’t as in depth, maybe, as it could have been.
During grad school, I had one job where I was actually working in a drone company. A lot of the machine learning that I was actually working on was looking at sensor data at different kinds of sensitive objects with the purpose of trying to combat overall gun violence with a drone that puts itself between a weapon and another human being.
The use case was something that could be used by law enforcement at traffic stops, large events, and outdoor gatherings — scan people from a distance and have an idea of whether or not they’re armed. Obviously, this is a super sensitive issue and as a grad student trying to work on this mostly machine learning solution, it was really difficult having conversations with my team about what is an acceptable failure threshold, how many false positives are acceptable, what are our limits here. I constantly felt like my work wasn’t good enough.
Many organizations we partnered with didn’t consider that it could directly impact life or death; it was hard for me to justify some of those decisions. I had this role for about six months and then a couple of weeks after I graduated, I went to the Data for Black Lives conference.
That opened my world to this realization that it isn’t just one project that I had, or one paper that I read. This wasn’t just an underlying feeling I had about algorithms working dubiously, but understanding almost every industry is using machine learning at this point and every single one is facing issues. So many problems in AI are about lack of representation in the data of people, so that tools work well enough for more people.

Hetal: You’ve previously spoken about doing gun detection in terms of actually protecting minority groups from threat of violence. Was that around the same time?
Ayodele: Exactly that. We, even as an organization, didn’t just want to bend to what law enforcement felt they needed, because that is disproportionate to not only policing habits, but the needs of the powerful, privileged majority in this country.
We had from the very beginning a set of rules, our drone is: not a defense weapon, not a weaponized kind of drone, it truly exists to indiscriminately protect people. So, we had some difficult conversations with law enforcement where they wanted this tool to only protect officers, and that wasn’t something we were going to build.
From a technical point, if a drone identifies someone in an aggressive stance, so holding an arm out holding a weapon, and it’s able to positively confirm that they’re holding a weapon (distinguishing from cell phones, lighters, other small devices) then the navigation system would position the drone in front of the weapon.
We made a decision in terms of not only working to protect officers if they are facing violence, but to protect any civilian group if they are facing violence.
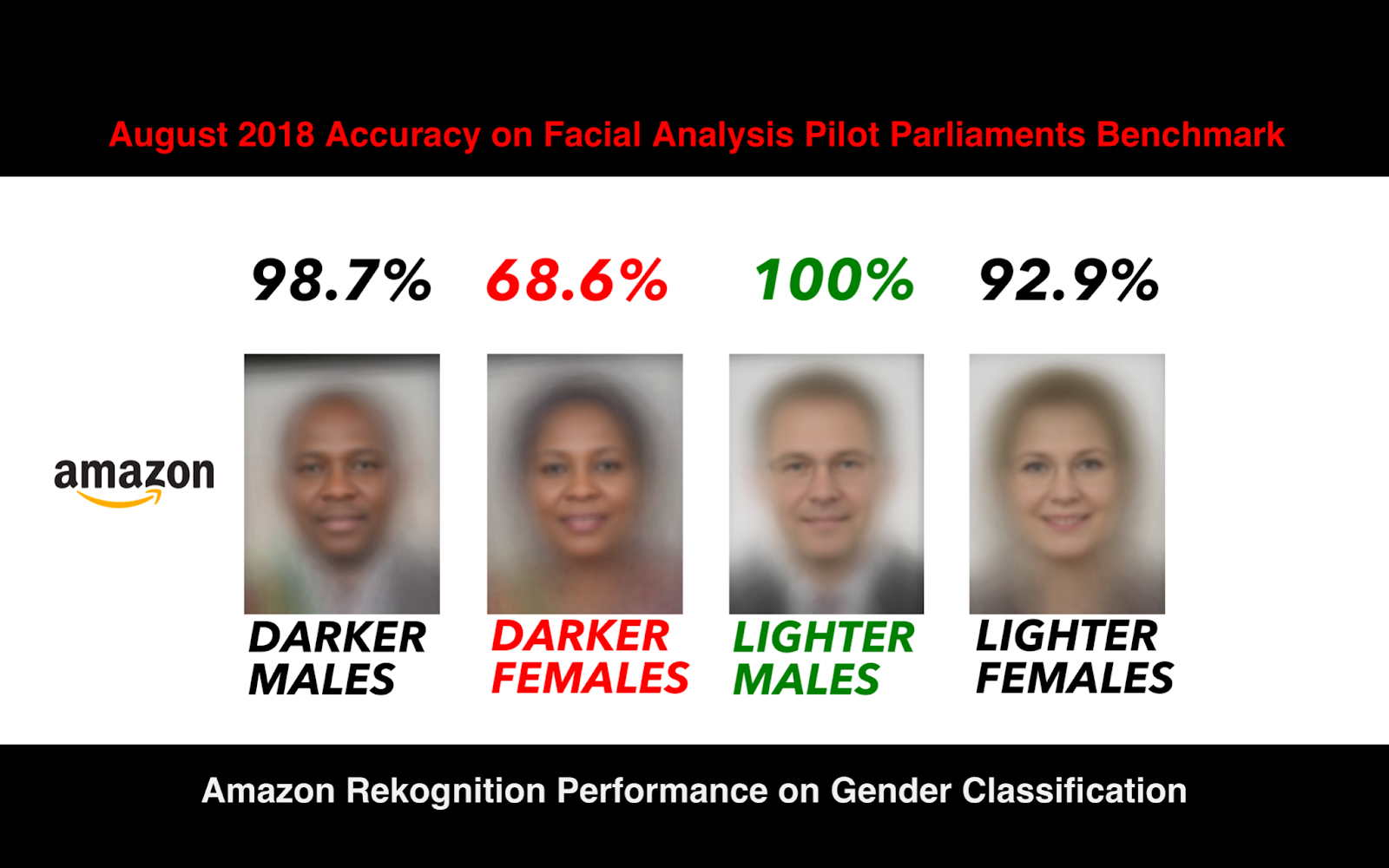
Hetal: There was news of a facial recognition software previously deployed by law enforcement that had a high success rate on light skin, but not as high on darker skin. How do we persuade groups to look at what is the accuracy of models within different subpopulations?
Ayodele: It’s incredibly difficult because it forces us to confront the end goals. As much as I would love tools to be just as accurate for everyone, I don’t want everyone to then have to be surveilled.
I think when we’re talking with governmental groups, we have a lot of power when we’re working with industry organizations like the IEEE and the ACM. Even with government groups that I’ve spoken to, I’ve consistently said, the ACM has recommended a ban on facial recognition, and facial recognition is not mature enough. Being able to point to those kinds of policy recommendations has been the most successful method I found.
Part of it is systemic, that some of the goals of these government groups and organizations are about outcomes that don’t prioritize health and needs as people of color to begin with. It’s really hard to say we just want things to be accurate for everyone, when at the same time, the goal remains to surveil specific groups.
We should work together on a policy level. It takes in part individual action on staying up to date with local policies being invested in, voting against or for specific policies that come up. I do think the implementation of something very similar to the GDPR in the United States will be a step on the way there. I think, eventually, we will be looking towards both industry and government groups, sort of an FDA for algorithms or an outside auditing board that has not just expertise, but has some reliability.
Hetal: Would ensuring that organizations have a diverse workforce help them confront it?
Ayodele: I would love to see organizations attempt to address or at least acknowledge that there is a power imbalance that many employees, despite what they want to bring, don’t always have the final decision on products.
So when it comes to listening, it really takes stakeholders who have either buy-in because they are personally passionate about this, or buying in because it is tied to their bonuses and it’s actually a priority as an entire organization.
I’ve seen companies do this — build metrics around accepting employee feedback, around how good stakeholders are in implementing these suggestions. Once we start to tie what seems like soft skill or soft goals, or diversity goals, to things like profit and revenue, or if we start tying them to our OKRs, I think we’ll see stakeholders start to make that change.
Especially when we’re getting to larger organizations, there’s always a power struggle between what people who are hands on think the company should do and those who may be a few levels away. I think being able to prioritize and really respect the expertise of the people on the ground is a great first step for companies.
Hetal: I just got into the show Insecure. Having gone back and consumed past interviews, a lot of effort was put in to ensure every character is appropriately lit. Because of that, you can see everyone’s expressions, which is not always the case in the media we consume, where you see one face with all of the richness of their emotions, but another face without.
Ayodele: I’d like to mention something even broader. Not only does Hollywood shape how we normal people think about AI, Hollywood also shapes how people perceive racial minorities and marginalized people. I think you have a great point around lighting and I think there’s another point to be made around having professionals who are capable of doing things like hair and makeup for black actors. That’s been huge in Hollywood recently, but we are deficient because of historical biases and it only continues to snowball. Maybe you don’t see the richness of someone’s full expressions when they’re acting, but that’s also coupled with not having talented makeup artists or people who don’t have the right colors on them on set for a particular character. That can drastically impact how we perceive people.
It is not just a Hollywood problem, but a vision problem. Actually my first grad school Capstone proposal was around investing in creating hardware that attempts to capture the darker skin tones with the same level of clarity. I think that is one of the biggest open areas for research.
And we’ll probably see the most drastic improvements in facial recognition in the next few years coming out of that. What we really need is drastic hardware improvements. Even if that only expands to really great consumer products, the whole point behind coded bias was that a lot of these out of the box facial recognition frameworks don’t work for people who have dark skin.
When our engineers and our AI students don’t have to face that same issue and can build projects without having to be concerned about those kinds of inaccuracies, I think we’ll start to see more equitable products that use facial recognition, and we will end up going back on that ban.
This article is part one of a two part write up. Check out part 2 here.