

This is the second article of my Reddit trilogy and in case you haven’t read the first article and you are interested in Reddit data scraping, do navigate over for a quick read. While I was intrigued by the idea of playing with Reddit data, I wanted to see how far I could go with Atoti compared to the article I read — Data Table using Data from Reddit. That was when I was introduced to spaCy by Philip Vollet, who commented that I could play around with named entities extracted from the posts.
spaCy is pretty easy to use, with plentiful examples around. In particular, I referenced this article from Real Python to kickstart my first Natural Language Processing (NLP) project!
Quickstart with spaCy
As with any python libraries, install the spaCy library. Also, I’ll need to download the models and data for English language, assuming the Reddit posts that I scraped are all in English as well.
Note: Run the following commands once for the setup
pip install praw spacy python -m spacy download en_core_web_sm
In the Jupyter notebook, let’s load an instance of the language model in spaCy.
import spacy
nlp = spacy.load("en_core_web_sm")Text preprocessing
Before starting on the extraction of named entities, text preprocessing is necessary to clean and prepare the data into a predictable and analyzable format.
Through preprocessing, I normalized the text:
- lowercase
- remove stop words (words that don’t add much meaning to the sentence) and punctuation symbols
- lemmatizes each token.
This way, the named entities extracted can easily be grouped to compute the number of times they are mentioned.
Applying the “NLP” function on a text generates a Doc object that gives a sequence of tokens for each post. I can then iterate through the tokens to perform the clean-up as shown in the example below. See the output after a given text is preprocessed:
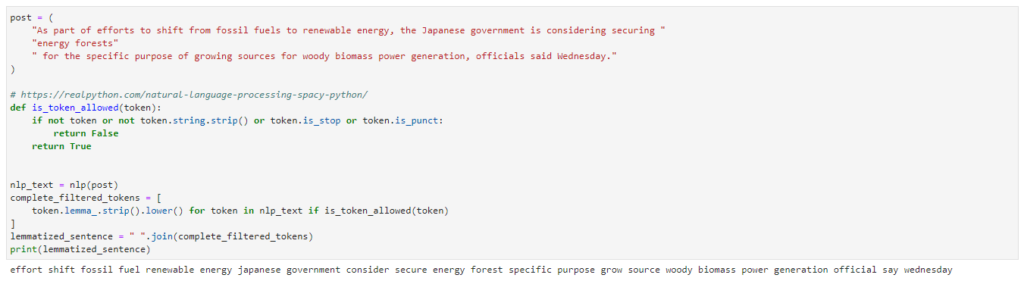
Named Entities Extraction
spaCy supports a long list of named entities. Instead of extracting all of them, I am going to focus only on the following entities from each Reddit posting:
- Organizations
- Person
- Geographical Locations
- Events
- Product
- NORP (Nationalities/religious/political groups)
To do that, again I apply the “NLP” function to the preprocessed text to obtain the tokens for each post. Each token has an “ent” object that contains various attributes, one of which is the label which I will check for the named entities:
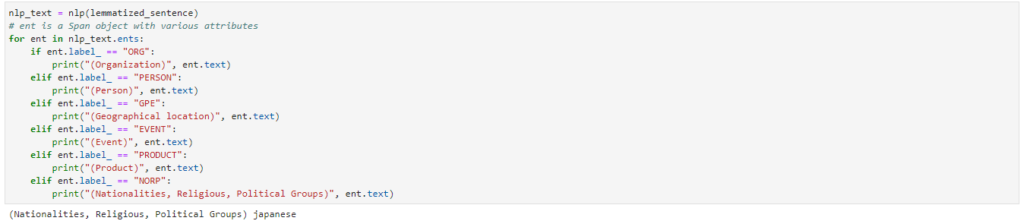
It’s a pity that it didn’t pick up “fossil fuel” as a product. Nonetheless, “japanese” has been classified correctly under NORP (Nationalities, religious, political group).
Now, that wasn’t too difficult. I will just have to integrate them nicely and I can perform some simple data analytics. Have a peek at what I aim to achieve next with Atoti!
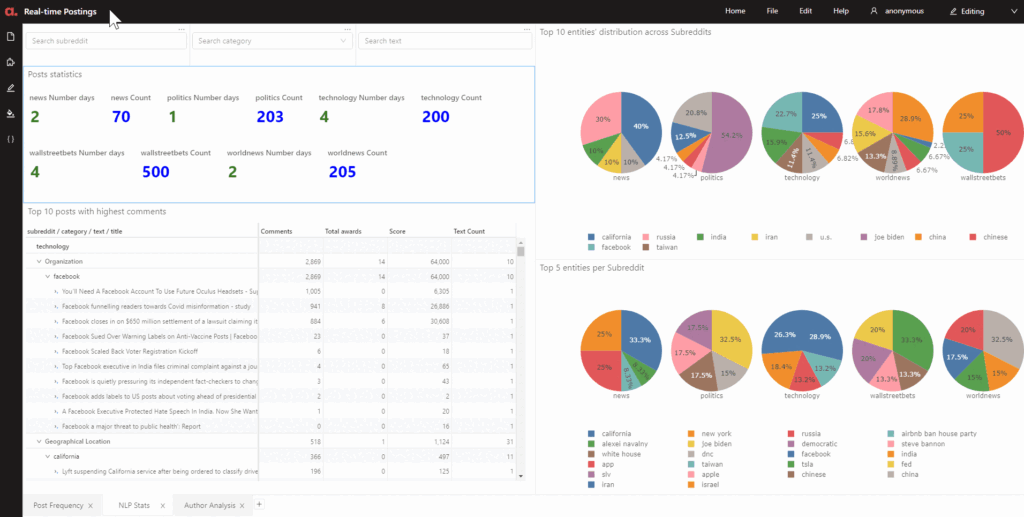
Stay tuned for the last part of my trilogy — Data exploration with Atoti. Can’t wait to see the effect of real-time dashboarding with Atoti!

