




Get a better understanding of your options for table creation with this quick guide exploring your options in Atoti Python API
Building out a project?
Are you at an exploratory phase where you have data in various files, unsure of what it contains and what columns will ultimately be useful in your data model? Or do you have a robust understanding of what you need in your data model and are ready to define your tables, even if the data is not yet ready?
Depending on your project, there are a few ways to create tables and load them with data. Read on for a quick explanation of your options and when it would make sense to use them.
Want more details? Visit Atoti Python API’s documentation for more information on anything referenced below.
We’ll keep this example straightforward, working with CSVs and dataframes alone. This means we’ll only need Atoti and Pandas for this demonstration and can create a no frills session.
import atoti
import pandas
session = atoti.Session()Create tables
There are two ways we can create tables in Atoti Python API.
Create and load
If we are in the data exploratory phase with our analysis, we can quickly create a table and load data into it in one fell swoop using one of the read_* functions. For example, read_csv() is used below. This will create a table and load in data based on what is already present. In our example, we have a CSV with order data.
orders = session.read_csv(
"s3://data.atoti.io/notebooks/table-creation-and-data-loads/data/Orders.csv",
keys=["OrderId"],
types={
"OrderId": atoti.STRING,
"ProductId": atoti.STRING,
"EmployeeId": atoti.STRING,
"CustomerId": atoti.STRING,
},
)
orders.head()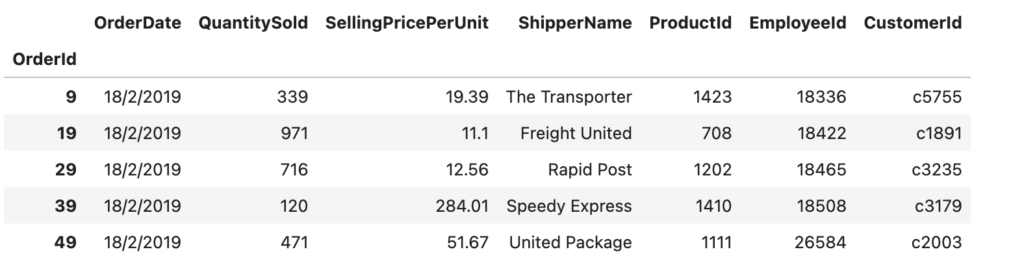
🗒️ It is a good idea to set the datatype of ID columns, though it is not necessary to do so.
There are other arguments we can set, including things like the table name, column mapping, and date patterns for date columns. These are not required, but can be set if we know something about the underlying data and what we ultimately want in our data model. Otherwise, these arguments will take on the specified default values outlined in its documentation, or, for arguments like types, be inferred based on a sample of the available data.
Let’s try this with our product data. We’ll set types, but not keys.
products = session.read_csv(
"s3://data.atoti.io/notebooks/table-creation-and-data-loads/data/Products.csv",
types={
"ProductId": atoti.STRING,
},
)🗒️ Like keys, defining types is optional. We’ll explore the benefits of setting up keys throughout this explainer.
In fact, the only required argument for read_csv() is the path to where our CSV is stored (or CSVs, since this accepts a glob pattern).
🗒️ If using a glob pattern, then we’ll need to set table_name.
There is nothing special about CSVs. We can just as easily read from a dataframe. To demonstrate, we’ll create a simple dataframe. This dataframe provides a contact name for each shipper. We’ll use read_pandas() to create a table and load in the data present in the dataframe.
shipper_df = pandas.DataFrame(
data={
"ShipperName": [
"Freight United",
"Rapid Post",
"United Package",
"Speedy Express",
"The Transporter",
"Federal Shipping",
],
"Contact": [
"Geoff Matthews",
"Payal Shah",
"Junqi Huang",
"Natalia Ramirez",
"Funmi Odunga",
"Liz Welds",
],
},
)
shipperContact = session.read_pandas(shipper_df, table_name="ShipperContact")🗒️ Like before, defining keys is optional to do. In fact, we did not set any in this example.
shipperContact.head()
Create then load
Often, our data modeling and our data loading steps cannot or should not be combined. For example, we may know what data model we need, but we don’t have the data yet. In this case, we can go ahead and create the tables we want, specifying things like the name of the table, what columns and types of data it will have, and what defines its primary key index.
Create tables
We’ll create two tables using create_table(), one for employee data and one for customer data.
customers = session.create_table(
"customers",
types={
"CustomerId": atoti.STRING,
"CompanyName": atoti.STRING,
"Region": atoti.STRING,
"Country": atoti.STRING,
"Address": atoti.STRING,
"City": atoti.STRING,
"PostCode": atoti.STRING,
"Phone": atoti.STRING,
},
keys=["CustomerId"],
)employees = session.create_table(
"employees",
types={
"EmployeeId": atoti.STRING,
"EmployeeName": atoti.STRING,
"EmployeeCountry": atoti.STRING,
"EmployeeCity": atoti.STRING,
},
keys=["EmployeeId"],
)🗒️ Like before, keys are not required, though a good idea to set.
Load data
The tables we created make no mention of where the data will be coming from. This gives us flexibility to create our data model and separately source and prepare our data before loading it. For example, if we have our customer data in a CSV file, we can use load_csv() to add data whenever that data is available. Let’s first take a look at a screenshot of the data we’re loading in.
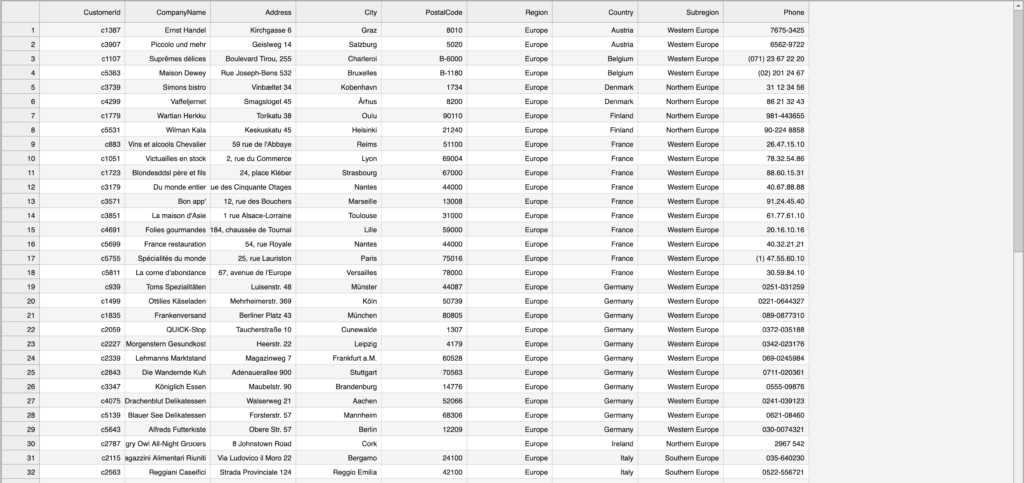
Two issues might come up:
- Our CSV has one more column than we modeled: it includes a Subregion which we never accounted for in the data model
- The CSV has a column called PostCode instead of PostalCode
We could (and likely would) clean this data up before loading, but for the sake of exploring this, let’s leave it and see what happens.
customers.load_csv(
"s3://data.atoti.io/notebooks/table-creation-and-data-loads/data/Customers.csv"
)
customers.head()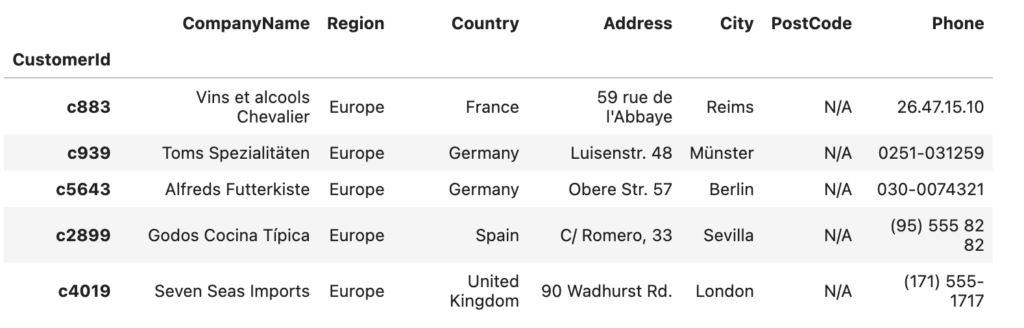
So, what happened with our two potential issues?
Nothing happened with the “extra” column from our underlying data. Phew!
For PostCode, it didn’t get populated. This is not surprising. How would it know which column of data to use?
Map data
Our underlying data may not have the same data model as what we set up when we create our tables. We can fix that by explicitly defining how we want our columns to map when we load our data. This is incredibly useful if our underlying data and our data model have different naming conventions.
customers.load_csv(
"s3://data.atoti.io/notebooks/table-creation-and-data-loads/data/Customers.csv",
columns={
"CustomerId": "CustomerId",
"CompanyName": "CompanyName",
"Address": "Address",
"City": "City",
"PostalCode": "PostCode",
"Region": "Region",
"Country": "Country",
"Phone": "Phone",
},
)
customers.head(7)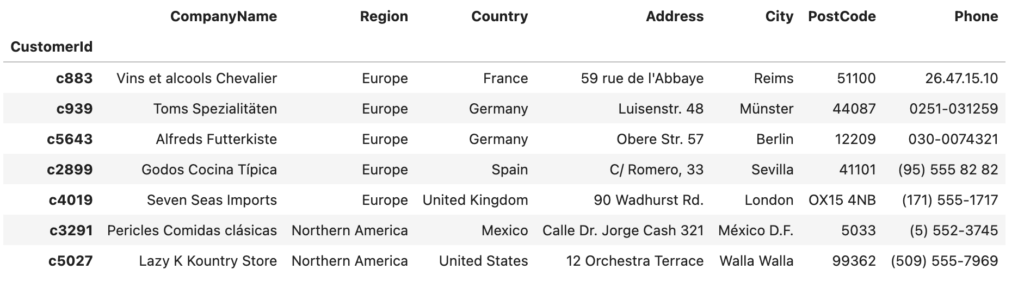
🗒️ Our data load updated our existing rows instead of creating new ones. It knew which rows to update based on our key setup.
Similarly, we can load in data from a dataframe, even if the dataframe has more columns. For example, the below dataframe has EmployeeRegion data that we did not account for.
employees_df = pandas.DataFrame(
data={
"EmployeeId": [
"12344",
"12695",
"18336",
"18379",
"18422",
"18465",
"18508",
"18551",
"18594",
"18637",
"18680",
"26584",
"63528",
"98635",
],
"EmployeeName": [
"Paul Henry",
"Louis Philippe",
"Steven Buchanan",
"Michael Suyama",
"Margaret Peacock",
"Joan Jet",
"Anne Dodsworth",
"Nancy Davolio",
"Laura Callahan",
"Andrew Fuller",
"Robert King",
"Eric Jeannot",
"Sean Tan",
"Shannon Lim",
],
"EmployeeCity": [
"Paris",
"Lyon",
"London",
"London",
"Redmond",
"Kirkland",
"London",
"Seattle",
"Seattle",
"Tacoma",
"London",
"Paris",
"Singapore",
"Singapore",
],
"EmployeeCountry": [
"FR",
"FR",
"UK",
"UK",
"USA",
"USA",
"UK",
"USA",
"USA",
"USA",
"UK",
"FR",
"SG",
"SG",
],
"EmployeeRegion": [
"EMEA",
"EMEA",
"EMEA",
"EMEA",
"AMERICAS",
"AMERICAS",
"EMEA",
"AMERICAS",
"AMERICAS",
"AMERICAS",
"EMEA",
"EMEA",
"ASIA",
"ASIA",
],
},
)
employees.load_pandas(employees_df)
employees.head()
🗒️ We do not have the ability to define a mapping between our dataframe and our table columns when working with load_pandas.
Load additional data
Atoti supports incremental data loading, both for tables created via read_* and those created via create_table().
For example, order data is likely going to evolve regularly. It would be nice to be able to keep enriching our order table with new information. Let’s create a dataframe with new order data.
order_df = pandas.DataFrame(
data={
"OrderId": [
"105689",
"105689",
],
"OrderDate": [
"20/2/2019",
"20/2/2019",
],
"QuantitySold": [
512,
928,
],
"SellingPricePerUnit": [
34.16,
52.89,
],
"ShipperName": [
"Speedy Express",
"Rapid Post",
],
"ProductId": [
"1202",
"708",
],
"EmployeeId": [
"18508",
"18422",
],
"CustomerId": [
"c2003",
"c2003",
],
},
)
orders.load_pandas(order_df)🗒️ We ensure our column names match when loading data from a dataframe.
Bonus: Join tables
We’ve created these tables, it seems a shame to leave them all by themselves.
At any point after we created our tables, even before we’ve loaded any data in them, we can join our tables.
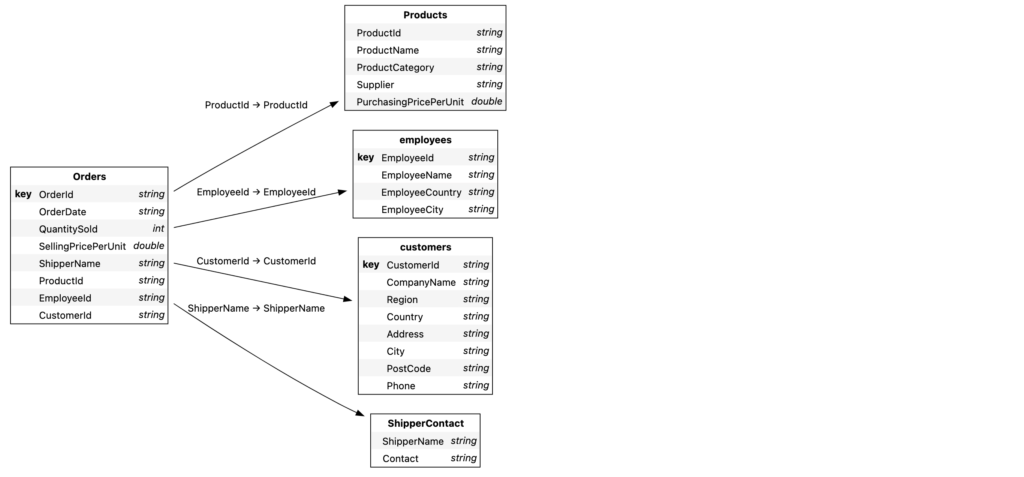
In our example, our order table is our most granular, and makes sense to use as our base table. Let’s join our product table to our order table, using the ProductId as our join.
orders.join(products, orders["ProductId"]== products["ProductId"])Let’s see what this did. We can use the schema property of our tables to view.

Do we need to define our mapping? Let’s try joining the employee and customer tables to orders, without specifying how.
orders.join(employees)
orders.join(customers)
session.tables.schemaAnd now our schema looks like:

And why did we spend so much time on those keys? Try running the below cell …
orders.join(shipperContact)… and you’ll get the following error.
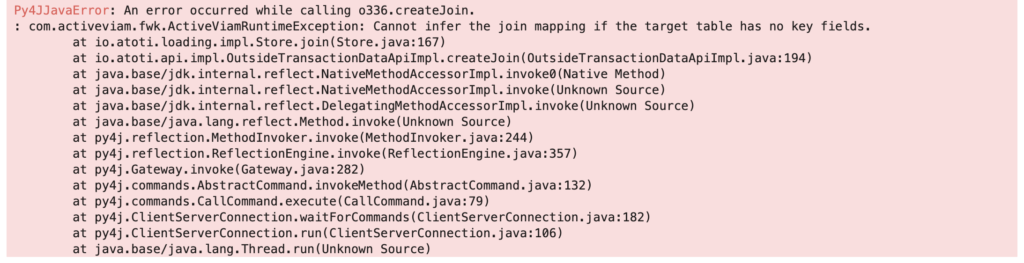
Yikes. We get that yuckiness because we never set up any keys for shipperContact.
When inferring how to join tables, Atoti looks for matched column names among the defined keys. We can still join these tables, we’ll just have to set the mapping to do so.
orders.join(
shipperContact, orders["ShipperName"]==shipperContact["ShipperName"]
)
session.tables.schemaAnd voila, our data modeling is complete!
We hope this guide helps you with your table creation and data loading needs. Want to explore more data? Check out our some of our guides on our GitHub repository or read our other articles on here atoti.io.


