Watching for file updates, appending the stores and listening to Apache Kafka
With Atoti, it’s possible to plug onto “live” data feeds and continuously update the notebook and the visualizations. The Atoti real-time capabilities consist of:
- Continuous queries feature: When new data is streamed into Atoti – such as a new record in the cube itself or a contextual update like a stock price tick – the backend precisely computes the impact on the registered continuous queries, and only recomputes what has potentially changed. The cells that have changed (and only those cells!) are refreshed in the real-time dashboards.
- Real-time data sources: Atoti naturally accepts multiple heterogeneous real-time data sources, see examples below.
- Real-time dashboards as illustrated below.
In this post, let’s look into the methods you can use to implement real-time data updates for your dashboards.
Assumptions
Before we begin, we are going to assume:
- you have some basic knowledge of Python and Jupyter Notebooks
- A multidimensional data cube has been created using the Atoti library for this article
You could refer to the Getting started with Atoti if you need more information on the basics with Atoti.
Reference example
We will discuss an example from the finance industry – a real-time market risk dashboard – to illustrate the three methods for implementing real-time with Atoti:
- market data feed via append method
- sensitivity file updates
- live trading activity messages delivered through Kafka
You can download the reference notebook from this link: real-time risk in the Atoti gallery.
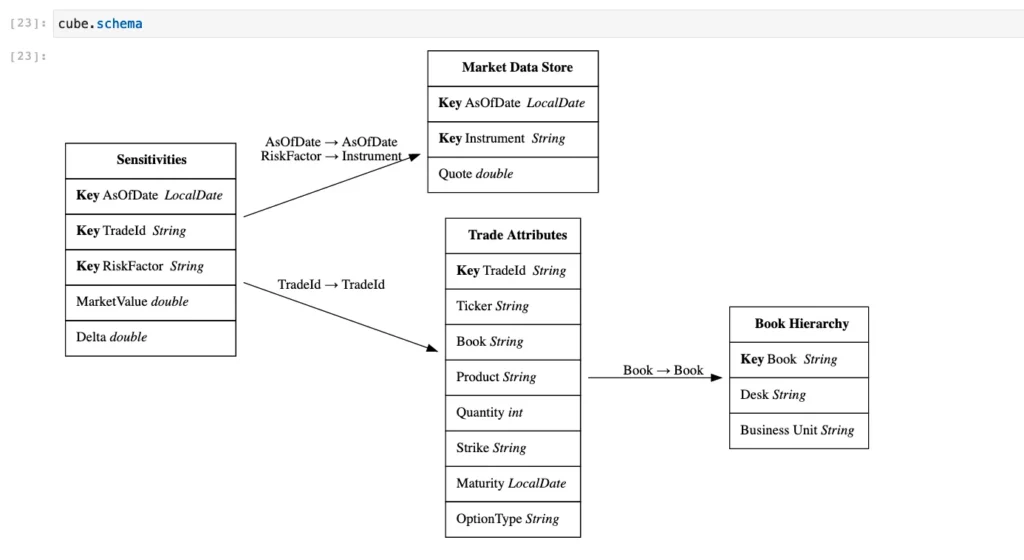
The data in our example is organized into the following datastores:
Let me jump straight to the examples of how you can enable real-time in your application.
append
You can use the “append” command to inject new records into any datastore.
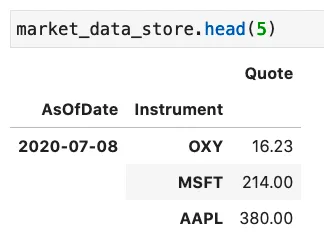
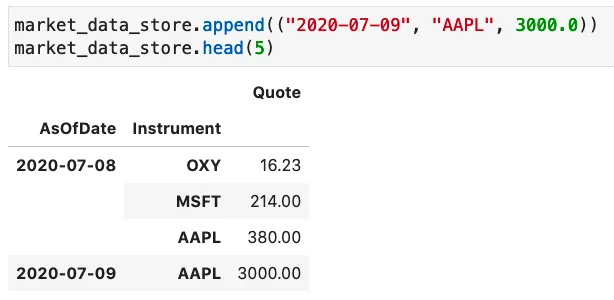
Let’s take an example. Initially the market_data_store holds quotes for the AsOfDate equal to 2020-07-08:
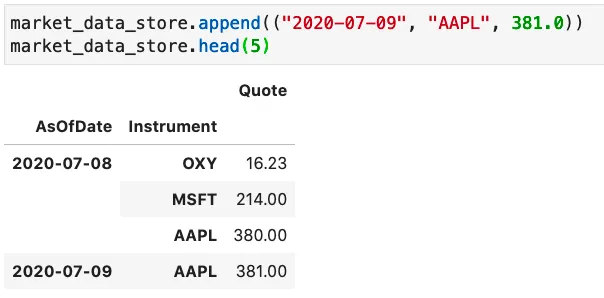
At any time, we can use the “append” command to inject new records, for example, let’s add a quote for AAPL and 2020-07-09:
Important note on the duplicate records: It is important to know that existing records having the same key_fields will be updated. For example, the keys of Market Data Store are AsOfDate and Instrument, we can update the quote for the instrument AAPL on the AsOfDate 2020-07-09 by running the below command:
watch = True
By creating a datastore with a watch = True we are telling Atoti to monitor file updates (specific file or a folder) and fetch the data automatically.
sensitivities_store = session.read_csv(
"risk_data.csv",
keys=["AsOfDate", "TradeId", "RiskFactor"],
store_name="Sensitivities",
types={"TradeId": tt.types.STRING, "AsOfDate": tt.types.LOCAL_DATE},
watch=True
)When an update is detected, Atoti will read the file and append the records.
load_kafka
Atoti provides a connector to Apache Kafka. Please refer to the Atoti doc for complete documentation, here let me provide you with an example of using load_kafka with a custom deserializer.
In our imaginary use case, a trading platform is sending new trades through a message bus, for example:
{
"AsOfDate": "2020-07-09",
"TradeId": "New_Trd_Test",
"Ticker": "OXY",
"Book": "EQ_VOL_HED",
"Product": "EQ_Option",
"Quantity": 45,
"Strike": -31.41,
"Maturity": "2022-10-01",
"OptionType": "put",
"MarketValue": 89.43
}We want to inject new MarketValue into the sensitivities_store, and trade details into the trade_attributes store. Let’s define a custom serializer in python:
# This serializer will pick up the trade attributes field from the trade message
def fetch_trade_attributes(record: str):
obj = json.loads(record)
fact = {}
for column in trade_attributes.columns:
fact[column] = obj[column] if column in obj.keys() else ""
return fact
# This serializer will pick up market value from the trade message. It also populates RiskFactor from the Ticker field:
def fetch_sensitivities(record: str):
obj = json.loads(record)
fact = {}
for column in sensitivities_store.columns:
fact[column] = obj[column] if column in obj.keys() else ""
fact['RiskFactor'] = obj['Ticker']
return factThis is not a very DRY principle compliant example, but I wanted to illustrate how to create a custom deserializer for use in the load_kafka method:
trade_attributes.load_kafka(
bootstrap_server="localhost:9092",
topic="trades",
group_id="atoti-trades-consumer",
deserializer=tt.kafka.create_deserializer(fetch_trade_attributes)
)
sensitivities_store.load_kafka(
bootstrap_server="localhost:9092",
topic="trades",
group_id="atoti-risk-consumer",
deserializer=tt.kafka.create_deserializer(fetch_sensitivities)
)Once the above snippet is run, Atoti will parse and append the records arriving through specified Kafka topic.
Real-time dashboards
By running the session.url command you can access Atoti’s app URL and start building real-time dashboards.
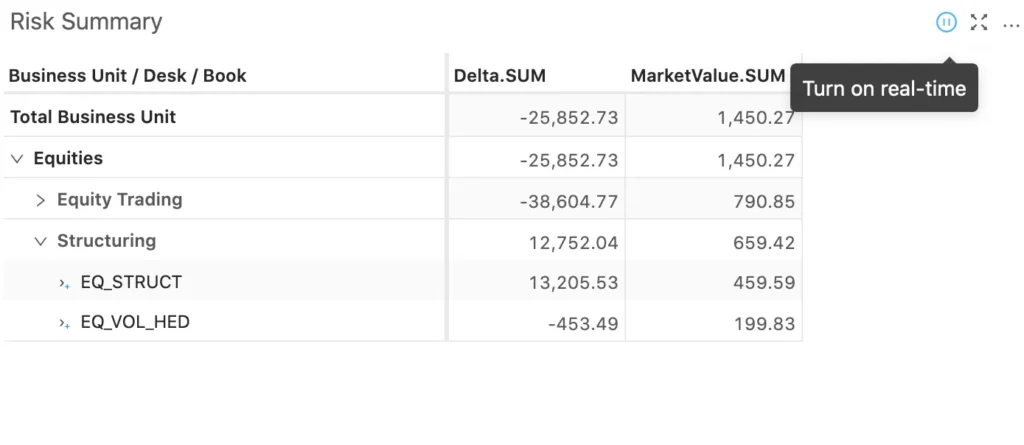
As mentioned at the beginning of this post, the Atoti platform supports the “continuous queries” feature, which enables widgets to automatically refresh the results every time a contribution changes in any data store. You can toggle between the below query modes for each widget in the Atoti app:
- “Turn on real-time”- widget subscribes to data updates from the cube. It will blink and receive the updated data every time contributors change the value in the cube.
- “Refresh periodically” – the widget will regularly query the backend. By default, query every 10 seconds. This setting can be changed using the state.
- “Pause query” – default for a new widget. Data is retrieved when the widget is reloaded or the query is edited.
You can toggle the query modes as shown in the following picture:
Here is an animation showing a dashboard summarizing real-time data:
Atoti data loading functions
Last but not the least, let’s talk about the following data loading functions of Atoti:
- load_pandas
- load_csv
- load_parquet
- load_all_data
These methods are used to inject new data into the cube during the development process. Although they are not designed to solve real-time needs, calling these methods will refresh the data, that’s why I would like to mention them in this post. After creating a datastore, for example, using read_csv method:
sensitivities_store = session.read_csv(
"risk_data.csv",
keys=["AsOfDate", "TradeId", "RiskFactor"],
store_name="Sensitivities",
types={"TradeId": tt.types.STRING, "AsOfDate": tt.types.LOCAL_DATE},
watch=True
)You can run:
sensitivities_store.load_csv(“risk_data_previous_cob.csv”)As a result, the new records are injected into the data store and can be accessed from the app immediately. The load_csv method is similar to the load_parquet and the load_pandas, please refer to the Atoti doc for more information about them.
Calling the load_all_data() method may also trigger the upload of the full dataset in the event of a sampled datastore. This method is part of the Atoti’s sampling package which aims at speeding up the development process by sampling the input data. Please refer to the Atoti doc to learn more about the sampling configuration.