

Combine Atoti and Data Warehouses to enjoy the deep-diving capability of Atoti on top of your existing data ecosystem
If you haven’t tried it yet, Atoti is a data analytics platform with a calculation and aggregation engine, a built-in visualization suite and an in-memory multidimensional data cube.
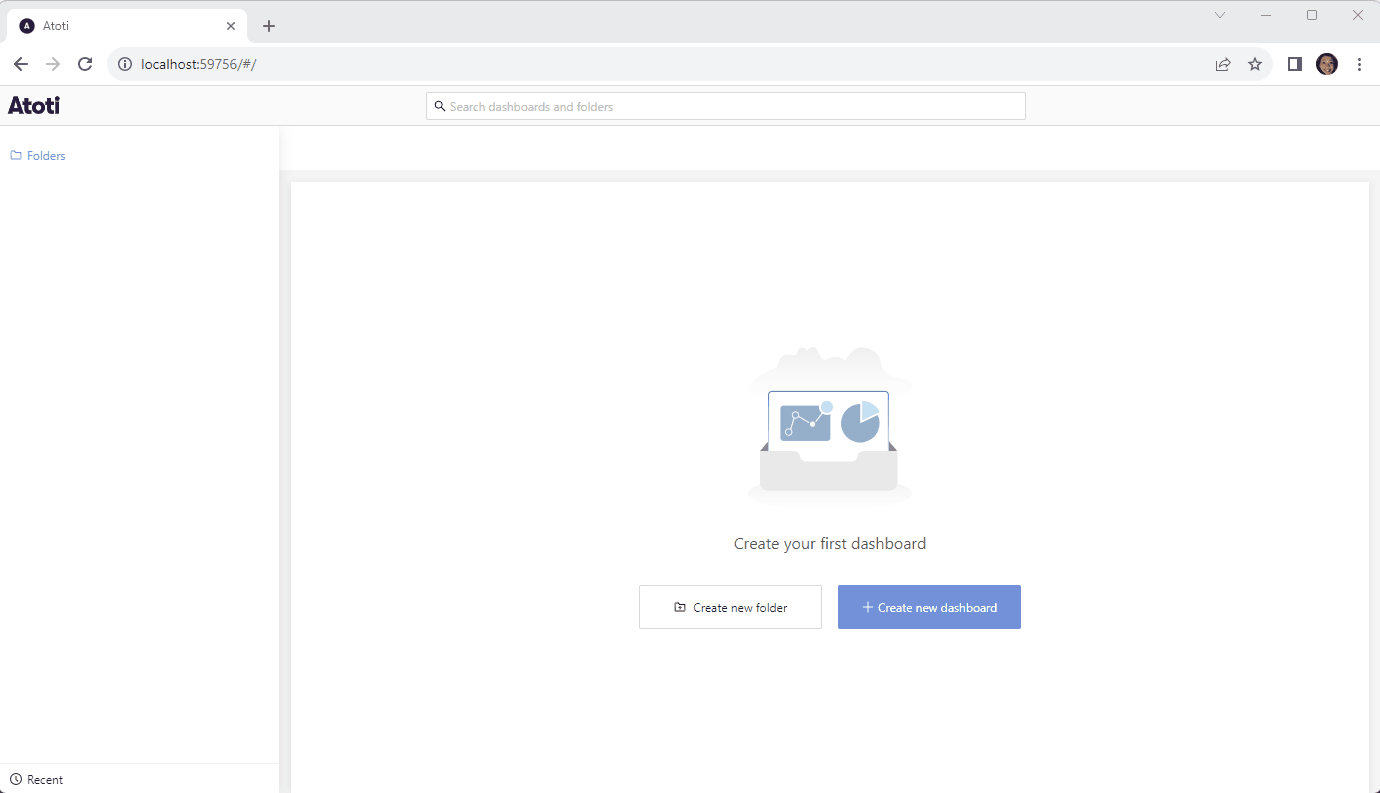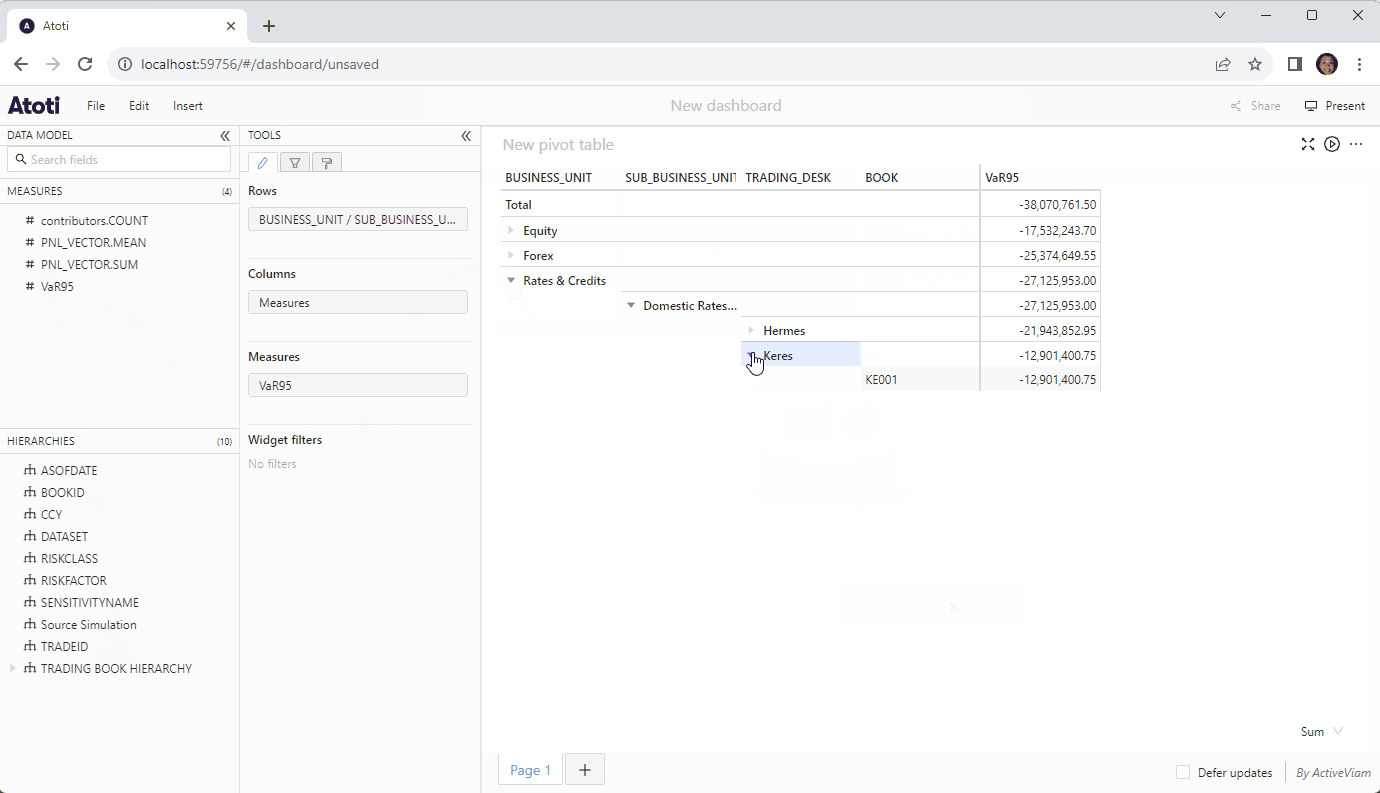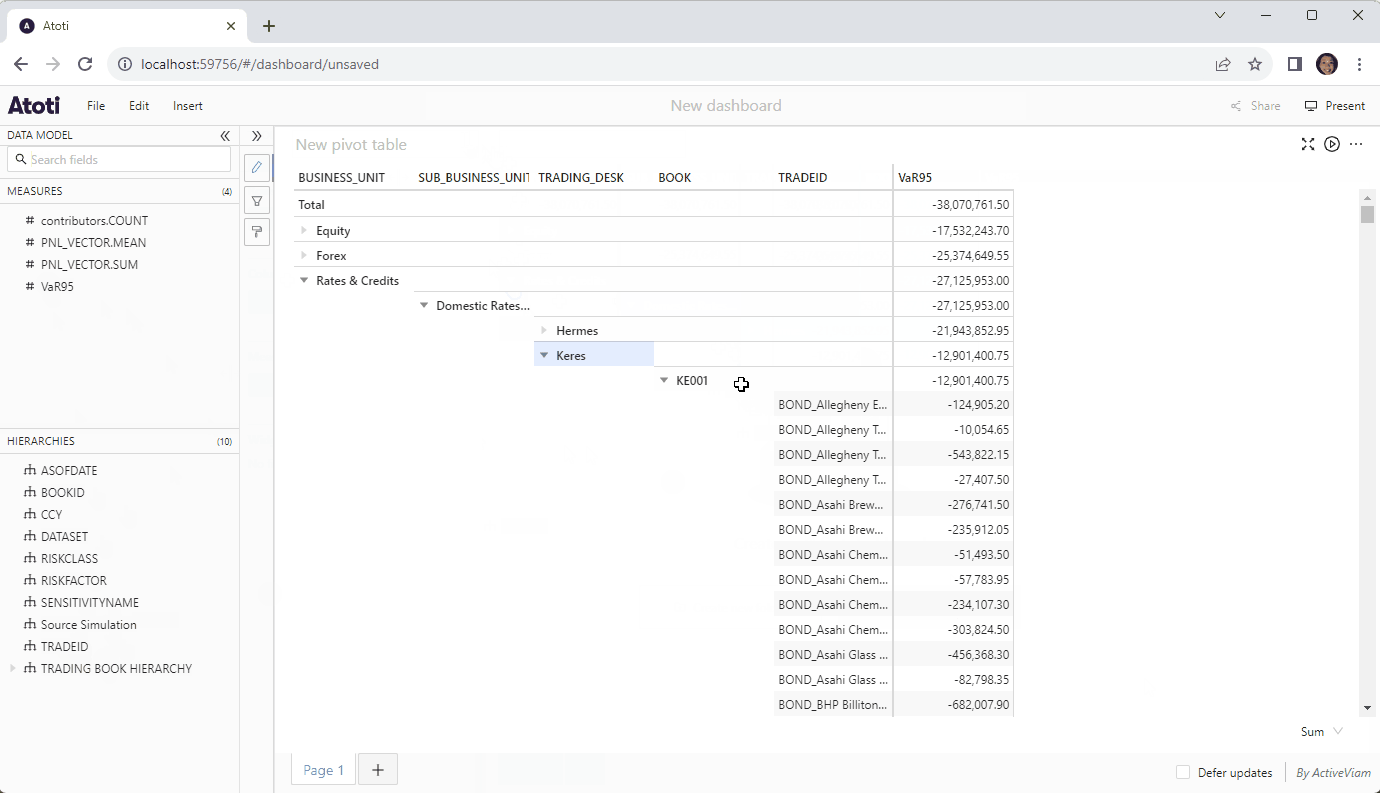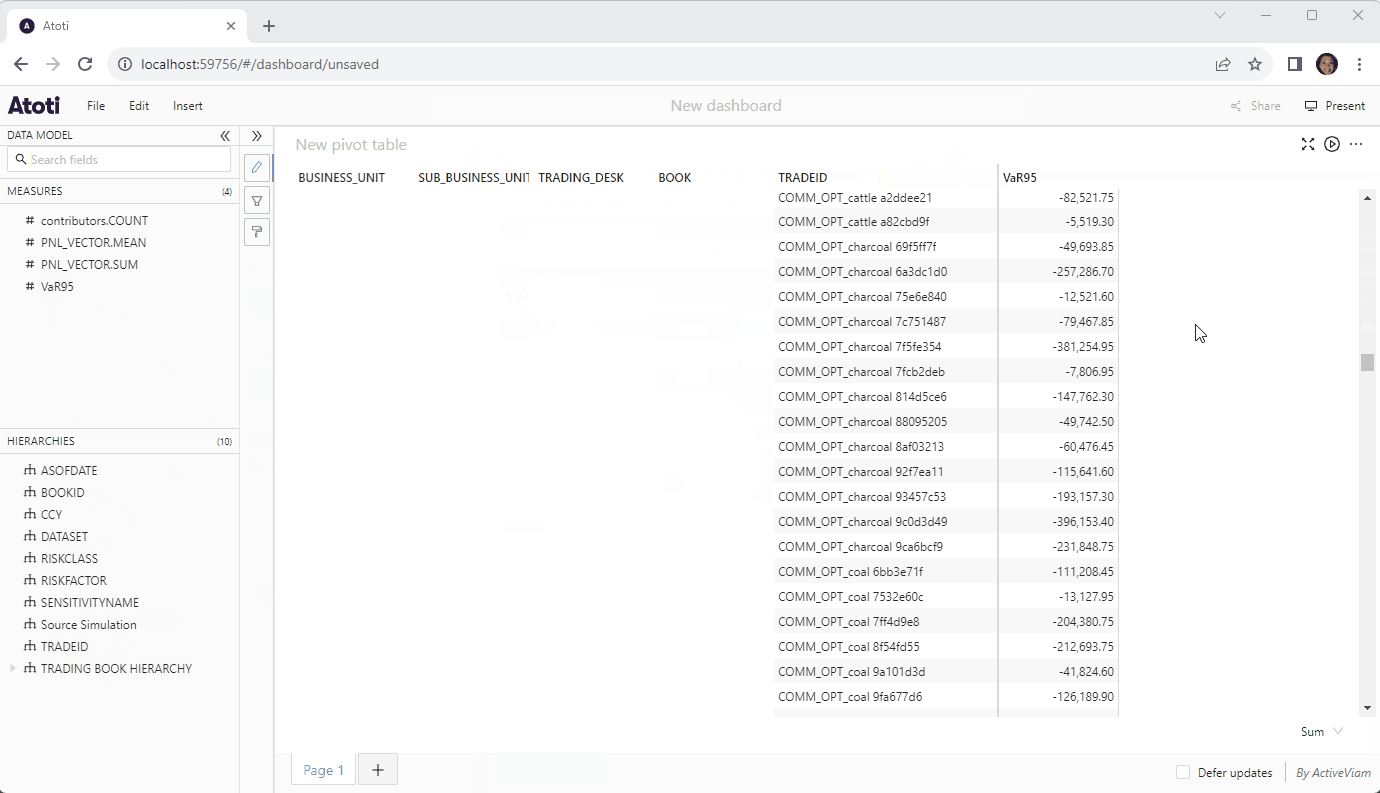
Until now, Atoti has been known for the instantaneous response of its easy to spin up in-memory cube and the ease by which we could define our calculations. But what if we had the ability to tie this to our many terabytes of historical data without having to continually write SQL code?
On top of native connectors, Atoti now supports on-premise and cloud-based data warehouses via DirectQuery. This means we can leverage the powerful multidimensional analytics capabilities of the Atoti semantic layer on top of any data that we have.
Atoti and its data sources
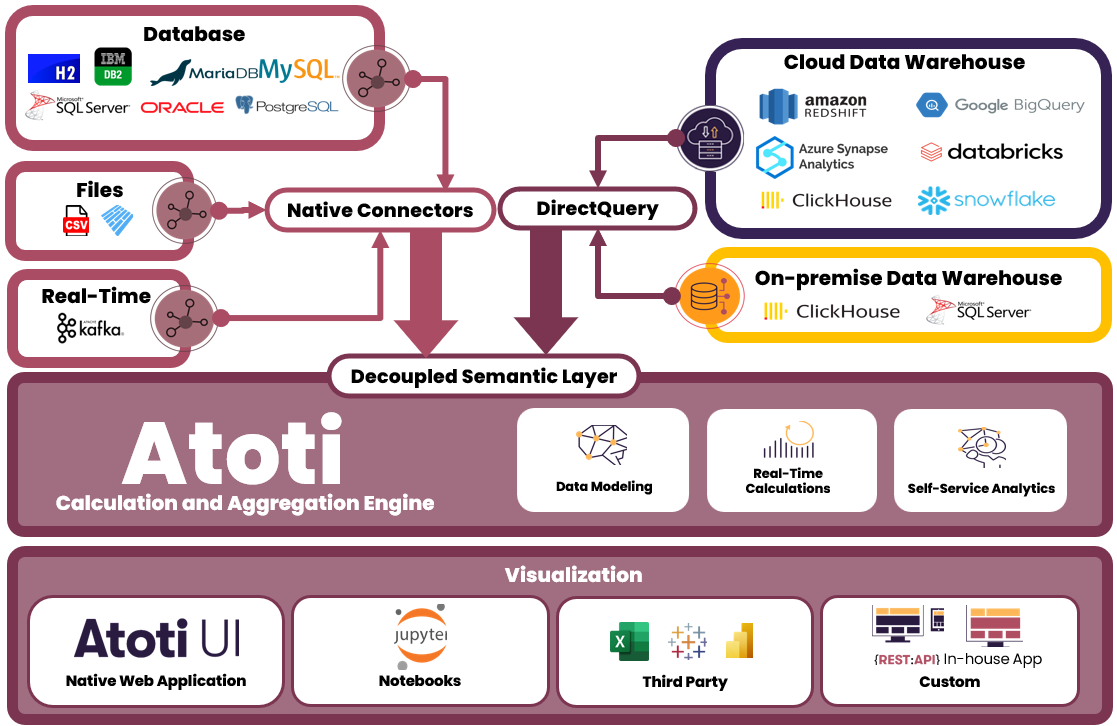
We ensure technology agnosticism by decoupling the semantic layer. This allows us to easily switch between different data sources without impacting the underlying data models and analytics.
Atoti’s native connectors
Atoti supports a range of native connectors that allow users to load data into the cube using CSV, Parquet or even from Python objects like Pandas DataFrame and Apache Arrow table. For real-time data loading, we can even integrate with Apache Kafka to load incoming messages instantly. And of course, Atoti can also load data from databases such as H2, Oracle database and MariaDB, etc.
The beauty of having these connectors is that we can easily load and integrate data of different formats and different sources into the cube within an instance of the Atoti Session. The data loaded into Atoti tables are held in memory and can be modified by incoming data.
Atoti’s DirectQuery
DirectQuery allows us to connect Atoti to external databases and thus add external tables from the connected database to the cube.
Unlike with the native connectors, we can only connect to one database instance in a single Atoti session through DirectQuery. Instead of keeping large volumes of data in memory, we leverage the scalability of the data warehouse for storage. This in turn reduces the need for memory on the Atoti server, and hence reduces infrastructure cost.
While native connectors load all of the data into the in-memory cube, DirectQuery does not behave the same way. The cube can be described as an aggregated cache on top of the database: it loads aggregated data instead of fact-level data. When the user queries the cube for a computation that can be performed in-memory thanks to the aggregated cache, there will be no queries to the external database. The query will be performed much faster.
Overcome limitation with Aggregate Provider
With DirectQuery, we query the data warehouse on-demand. Therefore, we are limited by the rate of return of query by the data warehouse. To understand how we overcome this limitation, let’s try to understand user behavior with respect to their data access.
Users often access data that is most recent and relevant to them. This is what we call “hot data.” This may be the data from the current date or current week.
Then, there is the data that is less relevant or less recent and therefore accessed less frequently. We call this “warm data.” This may be data from the previous weeks or months.
Last but not least, the rarely accessed data such as historical data from years back is known as “cold data.”
By understanding the frequency of data access and data relevance, we can achieve a trade off between the amount of queries made to the data warehouse and the amount of data to store in the memory of Atoti Server (say, up to several terabytes of data). This is achieved by caching the hot data in memory on Atoti server while the warm and cold data (tens or hundreds of terabytes of data) remain in the external database.
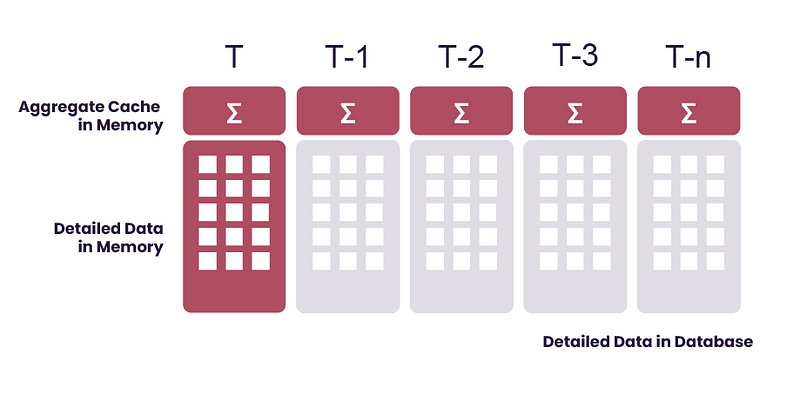
We perform data caching with the Aggregate Provider. With the “hot data” stored in-memory, we can now query the frequently accessed data without the limitation of query response time from the data warehouse. Therefore, we get to enjoy the same blazing fast performance of Atoti as before.
While we accelerate the most frequent queries by skipping the data warehouse, we preserve access to detailed and historical data. Users can still query the warm and cold data on-demand from the data warehouse via DirectQuery, albeit at a slower speed depending on the performance of the data warehouse.
Bonus Saving on the Pocket
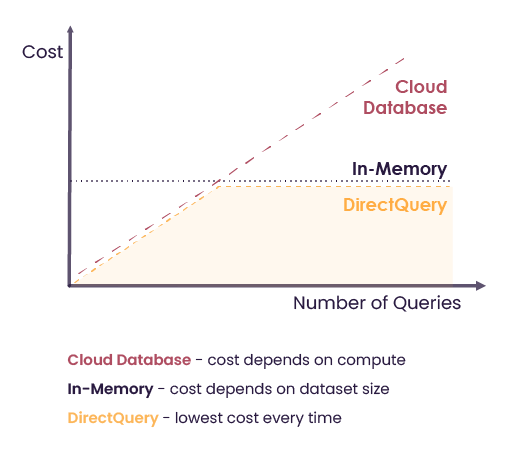
While the in-memory solution offers high performance, it also incurs higher cost on the hardware in comparison to having the data in the data warehouse.
However, by keeping only the relevant and frequently accessed data in memory, we effectively reduced the cost for the hardware compared to storing the full database in memory.
Likewise, by caching data in memory, we reduce the number of queries from Atoti to the data warehouse.
So, by putting in perspective the cost of memory against the number of queries, we see that DirectQuery offers the optimal balance between the in-memory solution and the cloud-based database.
Find The Right Balance
Atoti offers an evaluation license for the Python API. Give Atoti a try to experience the power of multidimensional analytics with in-memory computing. Find examples of Atoti with Google BigQuery, Snowflake and ClickHouse on the Atoti notebook gallery.
Unsure of how Atoti can fit into your data ecosystem? Reach out to ActiveViam for more information.


